
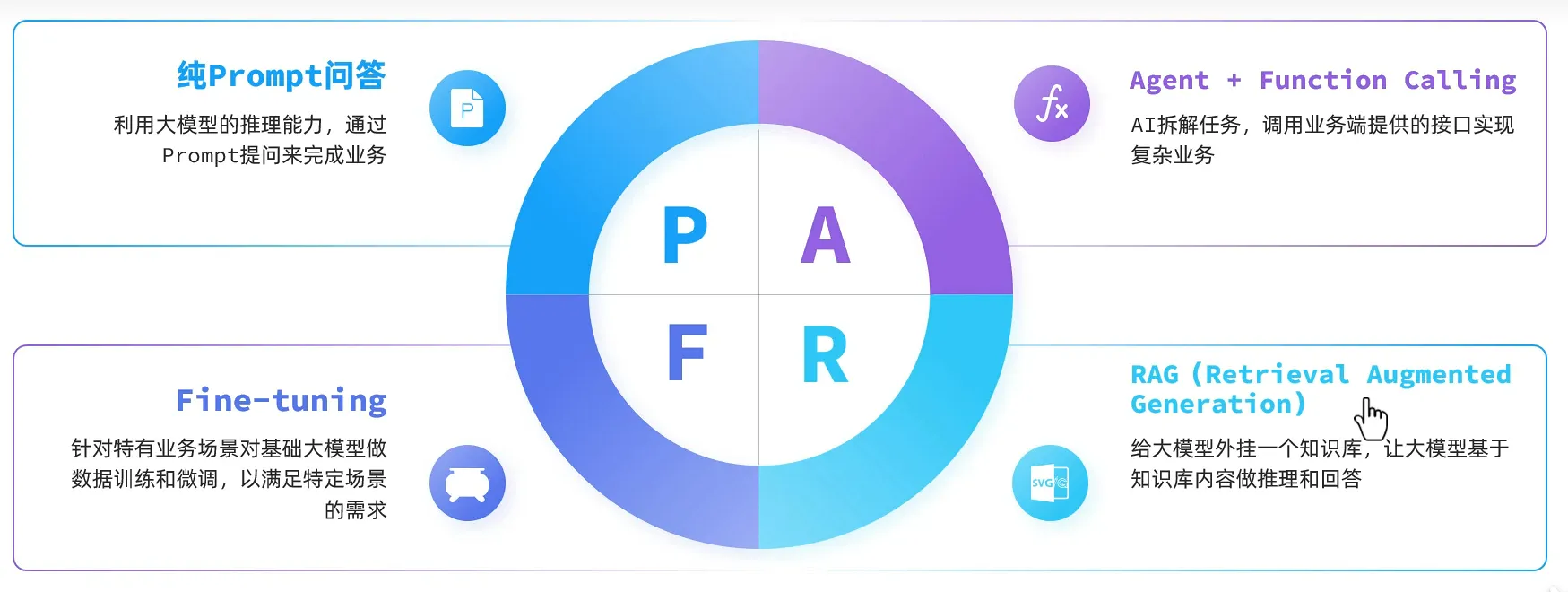
大模型开发
;)
在线文档:https://b11et3un53m.feishu.cn/wiki/DESQw9K4ji6Nf4kd9fzcwJTunmb
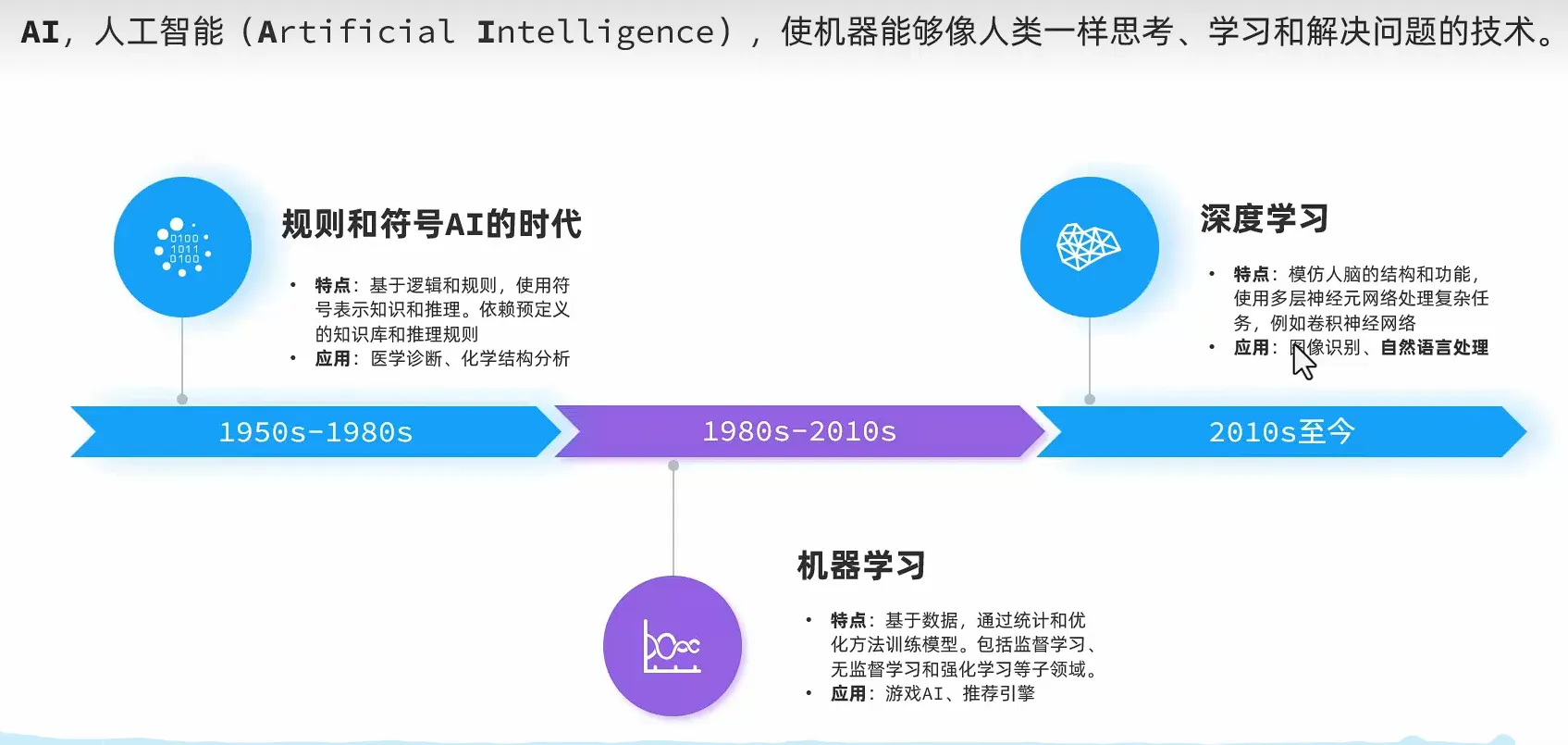
AI发展
- 符号主义
- 机器学习
- 深度学习 -> 自然语言处理(NLP) -> 大语言模型(LLM)

大语言模型
**Transformer**
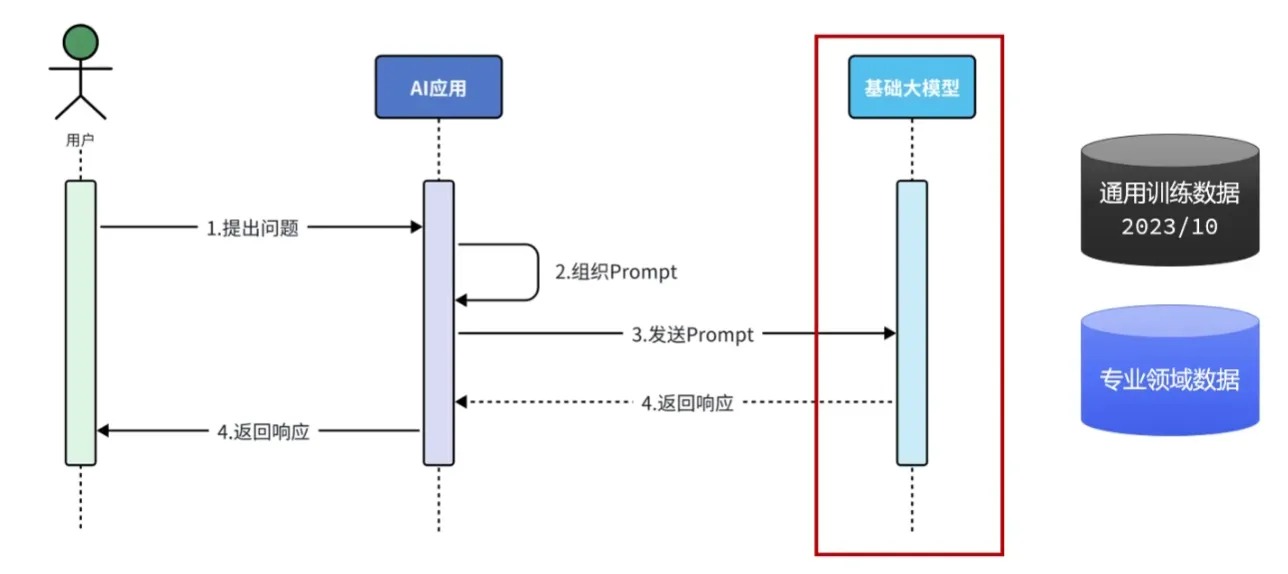
在**自然语言处理**(Natural Language Processing,**NLP**)中,有一项关键技术叫**Transformer**,这是一种先进的深度学习的**神经网络模型**,是现如今AI高速发展的最主要原因。我们所熟知的**大模型**(Large Language Models,LLM),例如**GPT**、**DeepSeek**)底层都是采用Transformer神经网络模型。底层原理
T:基于Transformer的神经网络 P:通过大量数据预训练,掌握自然语言规律 G:基于上文计算概率,生成下一个token模型部署方案
三种方案
- 云部署
- 优点
- 前期成本低
- 部署维护简单
- 弹性扩展
- 全球访问DNS
- 缺点
- 数据隐私
- 网络依赖
- 长期成本高
- 本地部署
- 优点
- 数据安全
- 不依赖外部网络
- 长期成本低
- 高度定制
- 缺点
- 初始成本高
- 维护复杂
- 部署周期长
- 开放API
- 优点
- 前期成本极低
- 无需部署
- 无需维护
- 全球访问
- 缺点
- 数据隐私
- 网络依赖
- 长期成本高
- 定制限制
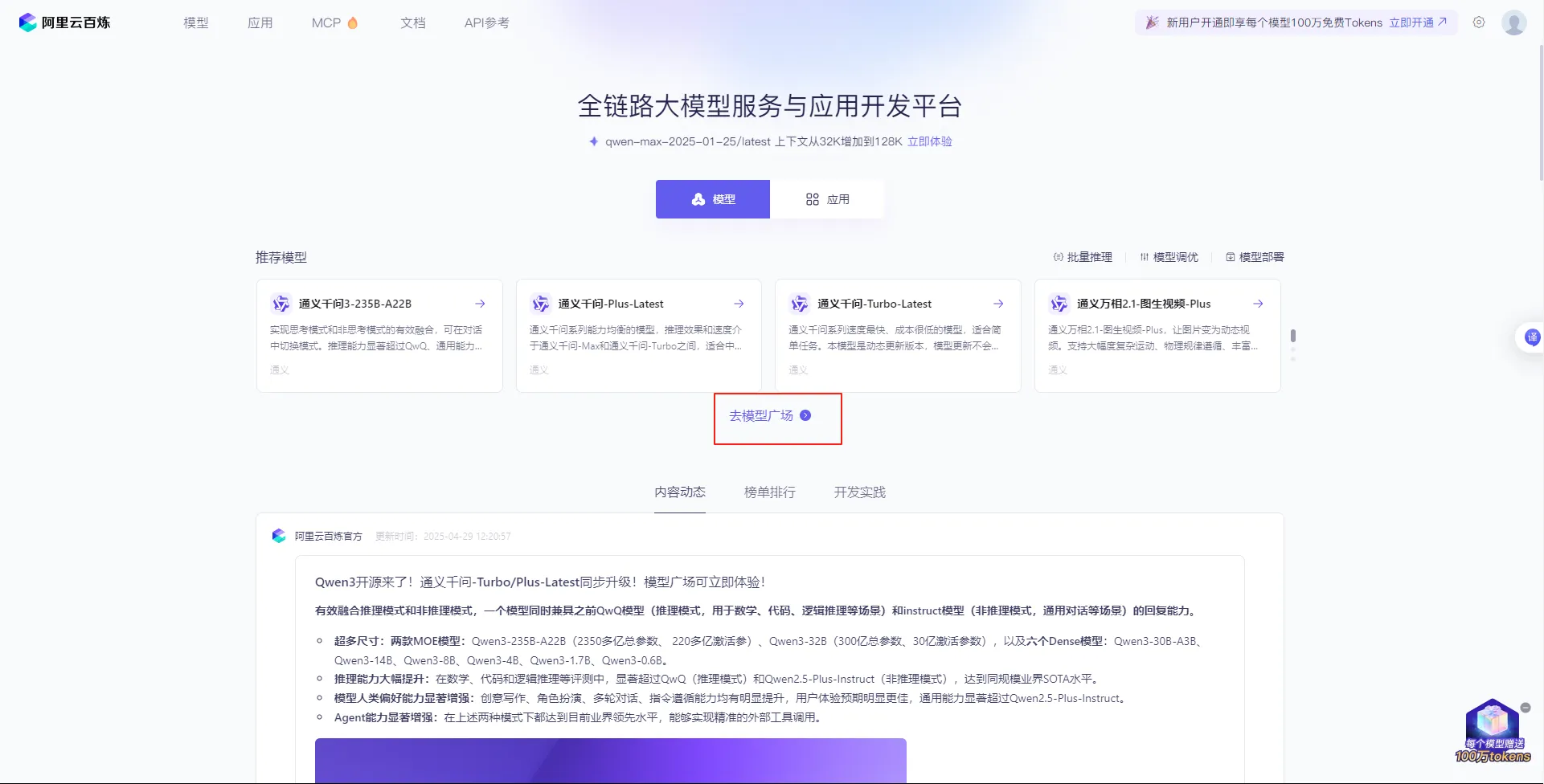
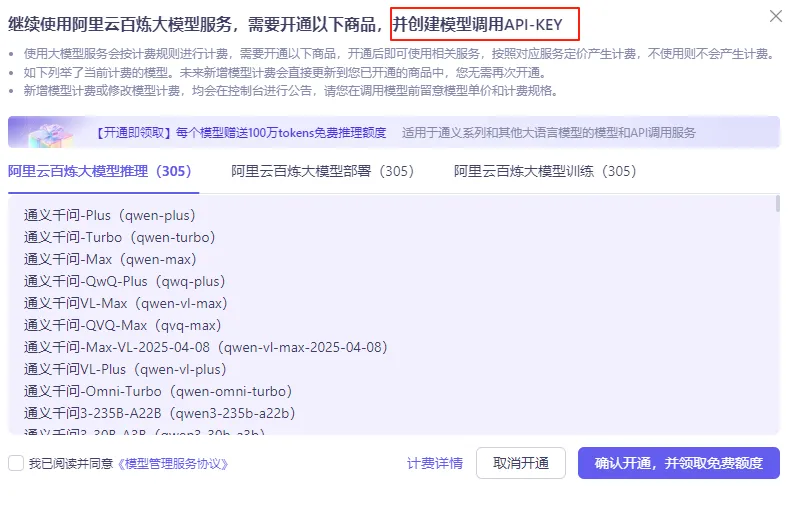
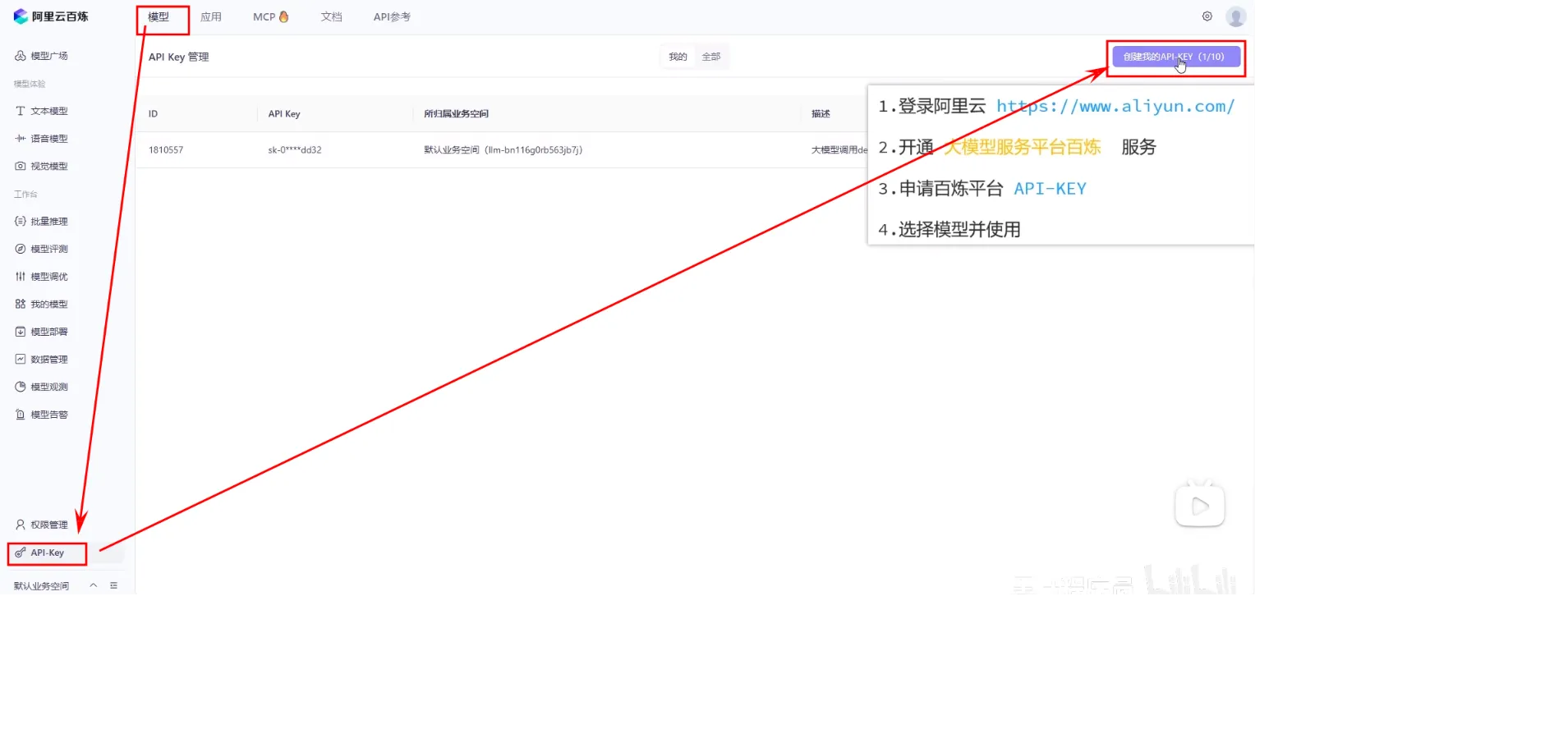
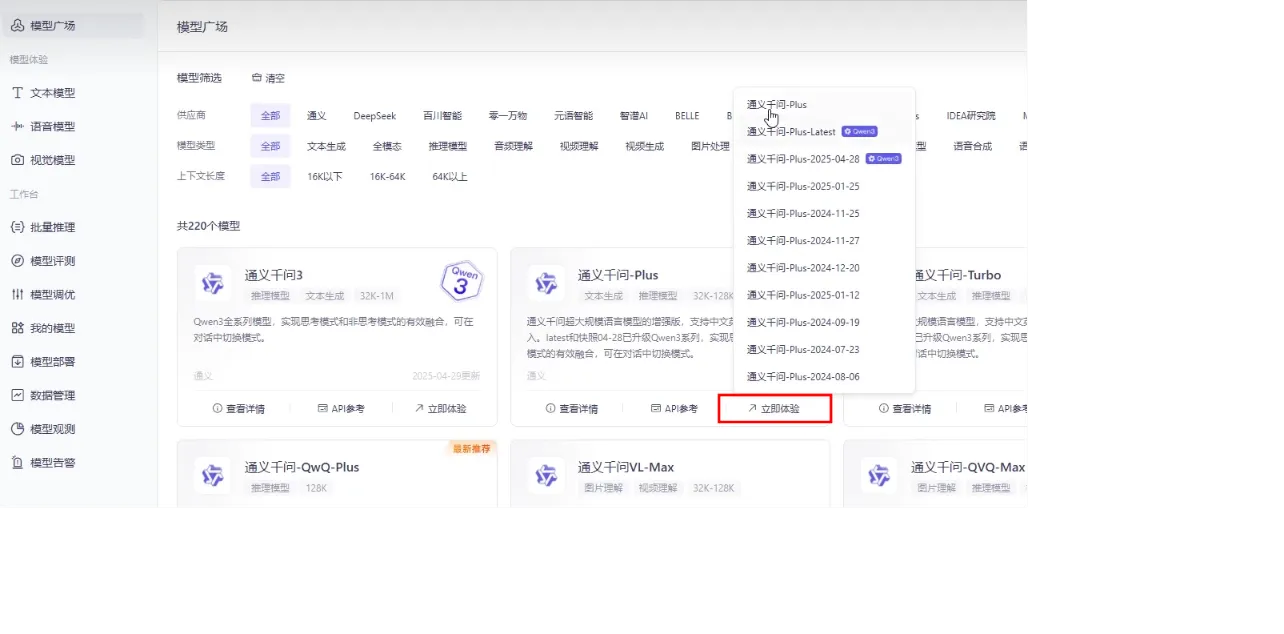
云服务
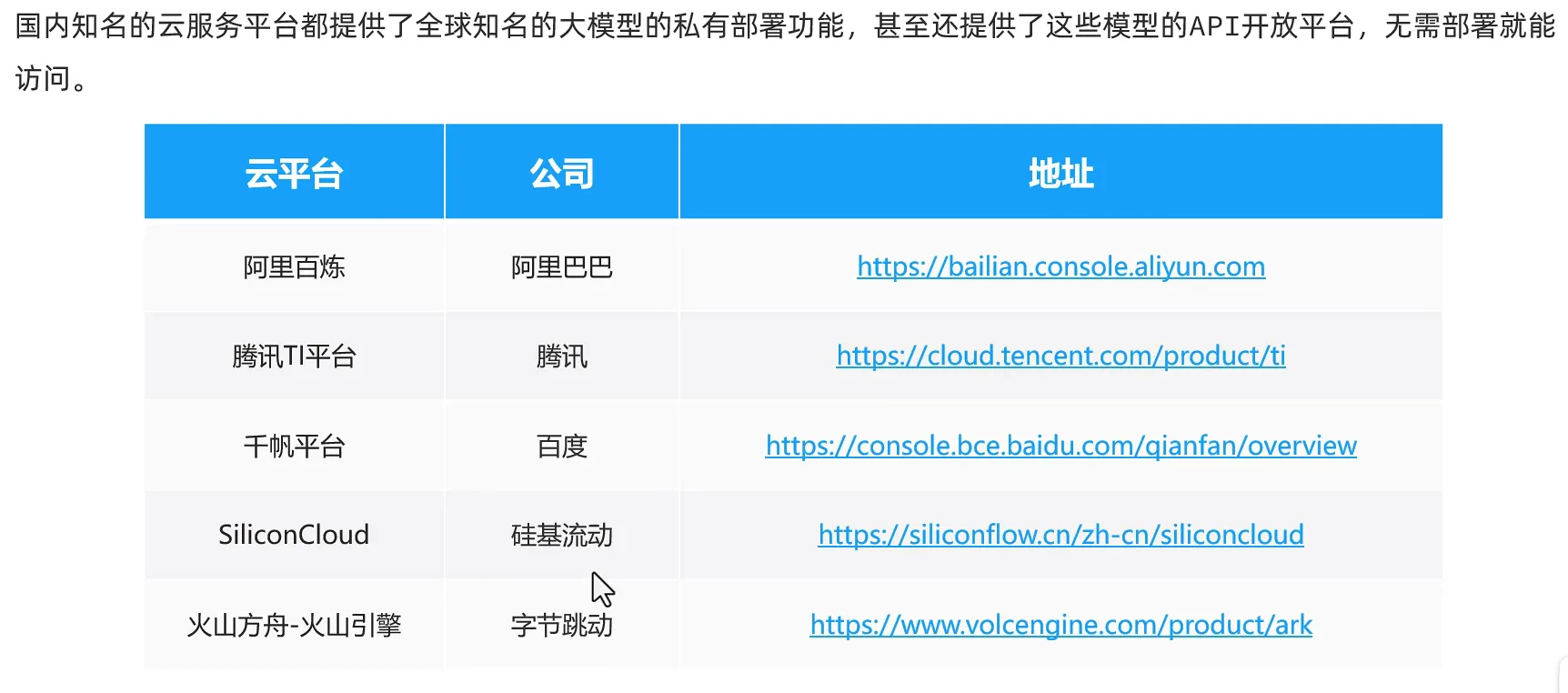
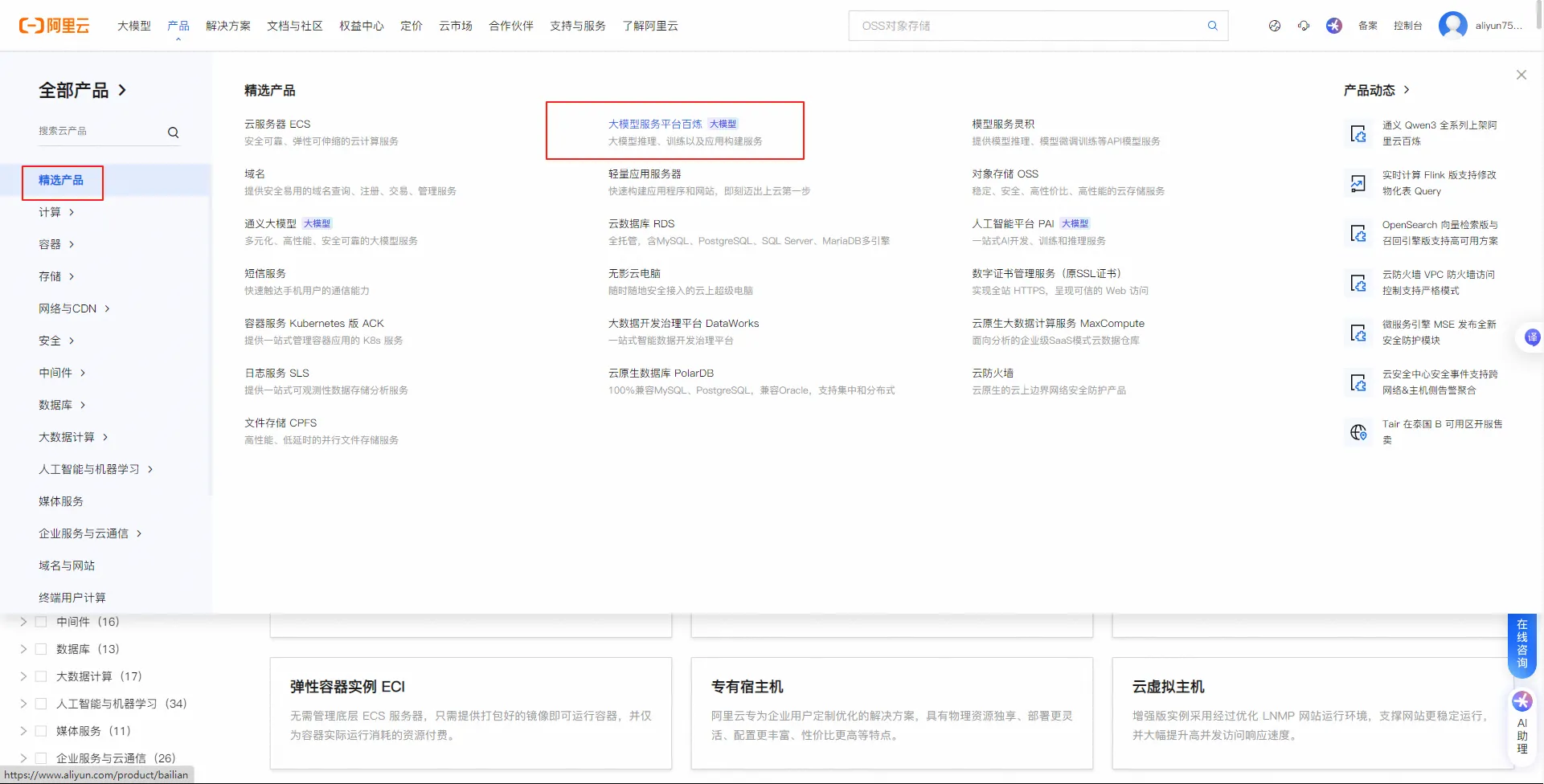
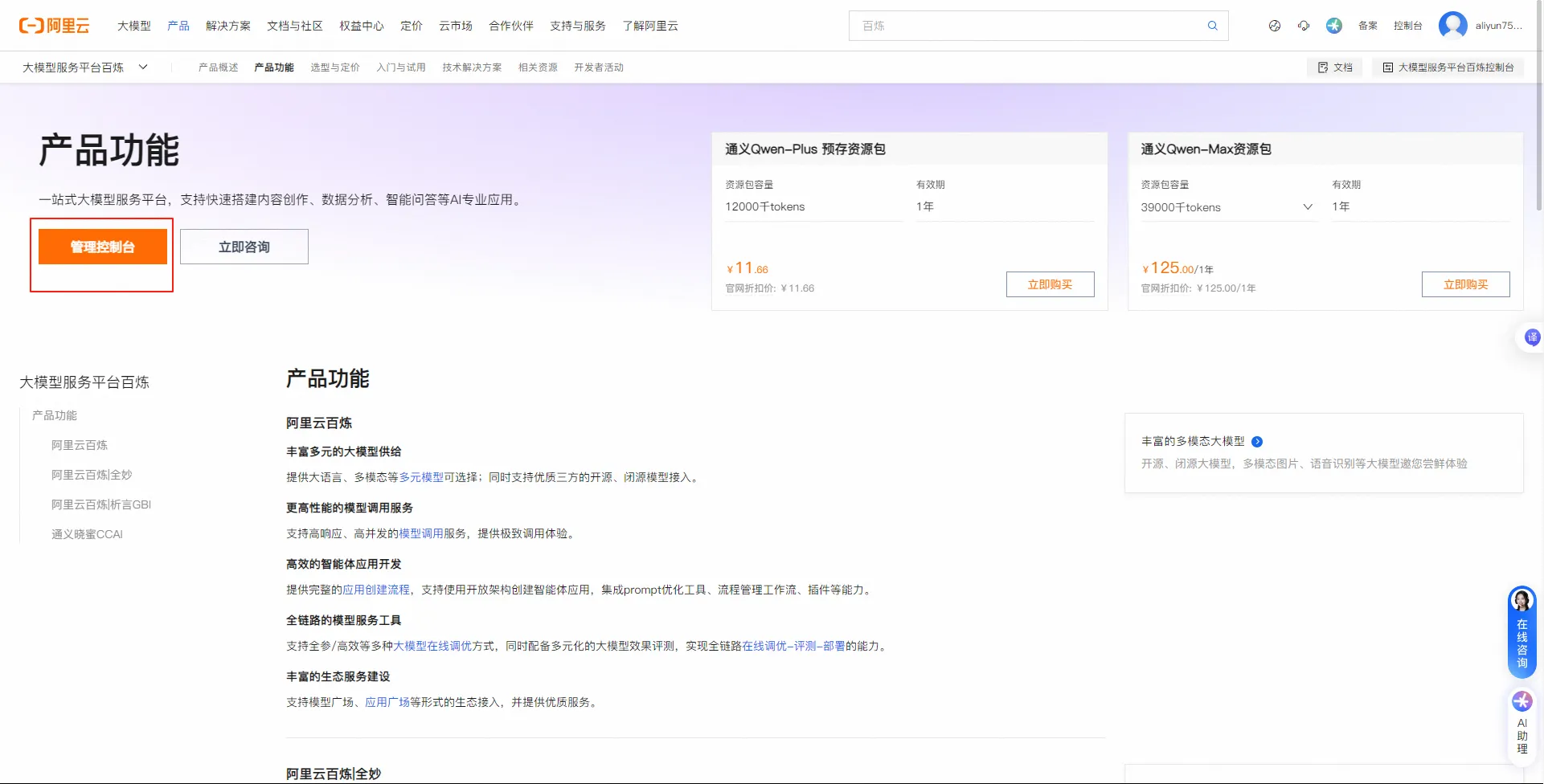
- 登录阿里云平台:https://www.aliyun.com/benefit?utm_content=se_1019887613
- 打开阿里云百炼:
- 打开控制台:
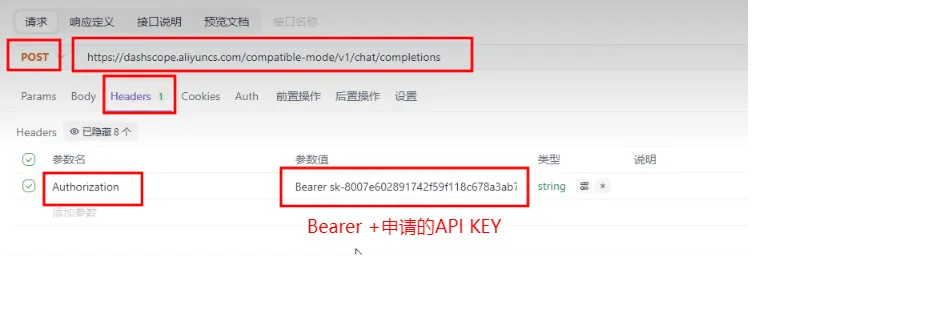
- 创建api-key:
体验模型将会消耗Tokens
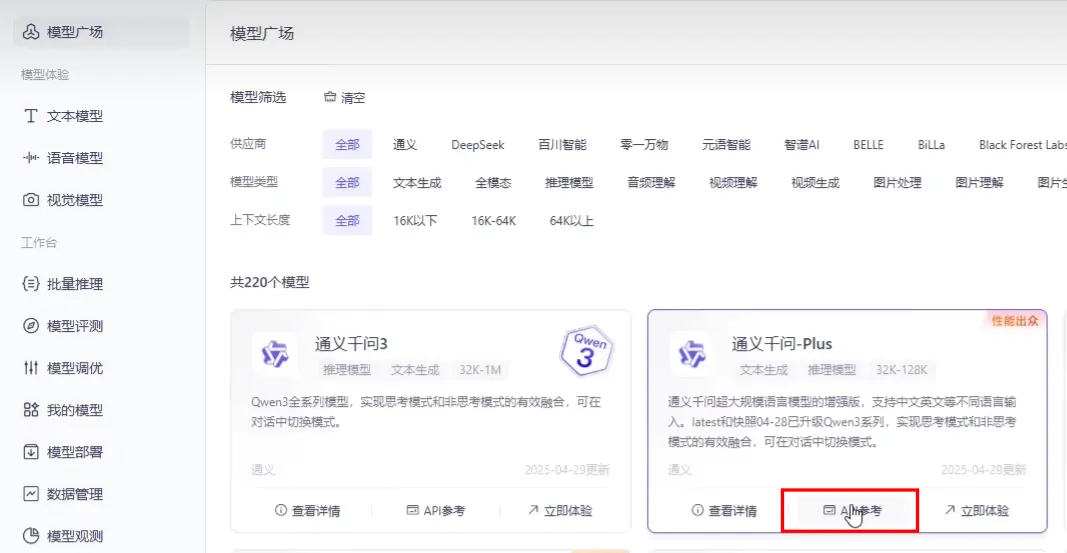
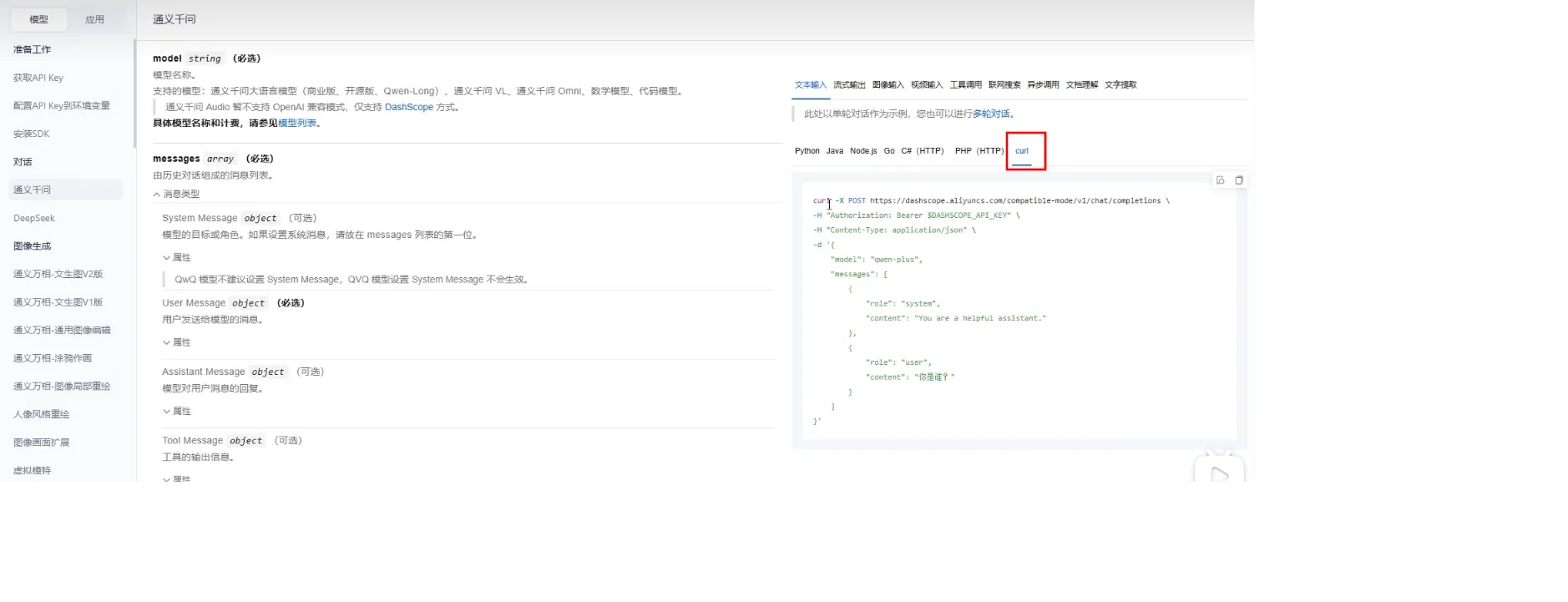
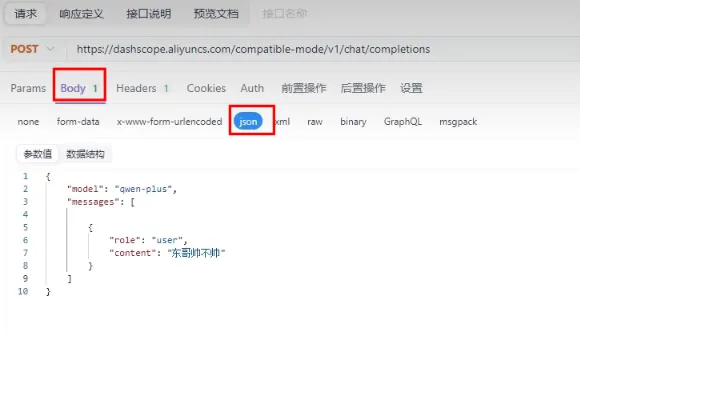
Apifox调用模型
-H:添加请求头本地部署
本地部署最简单的一种方案就是使用ollama,官网地址:https://ollama.com/下载ollama:
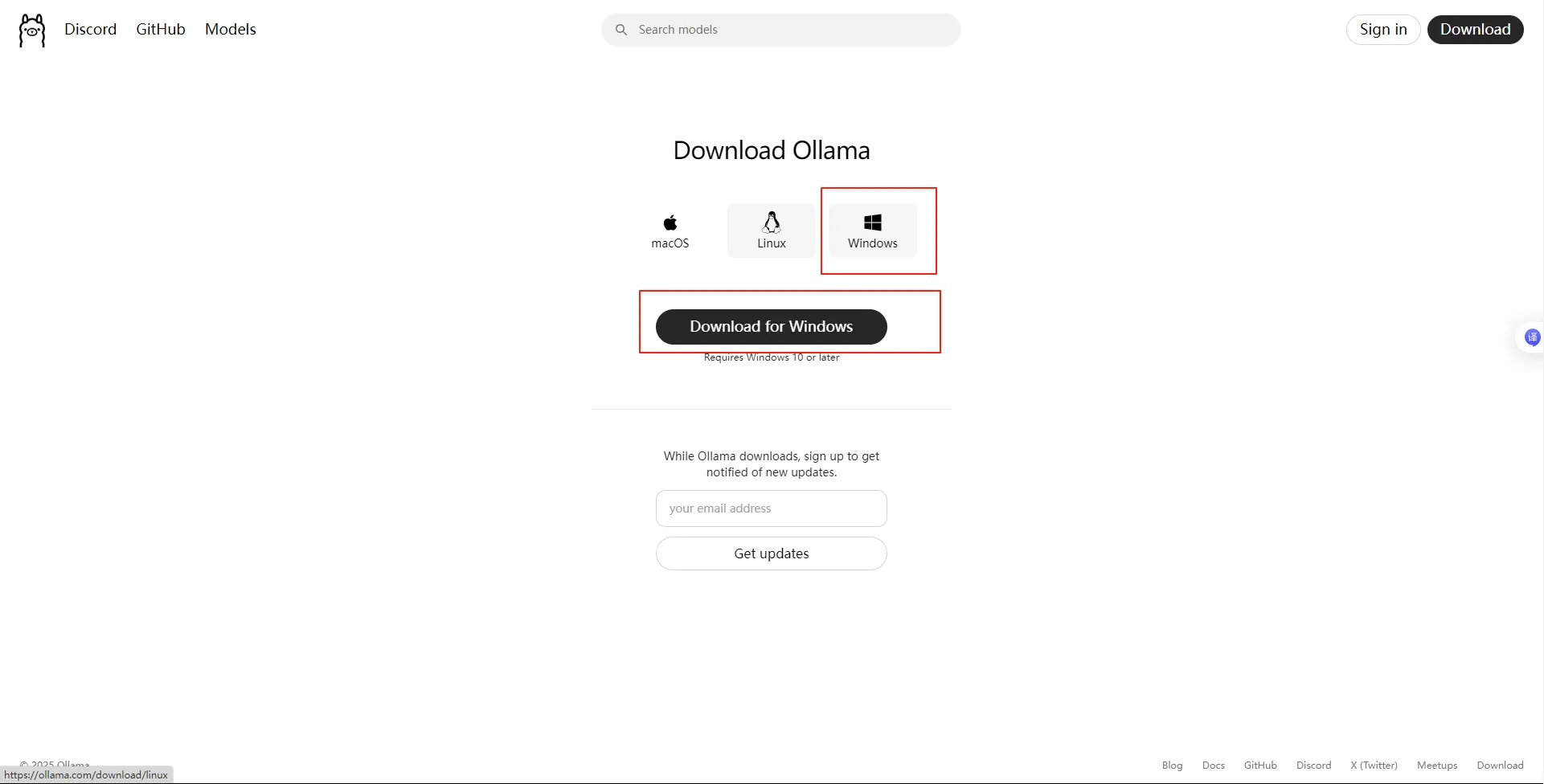
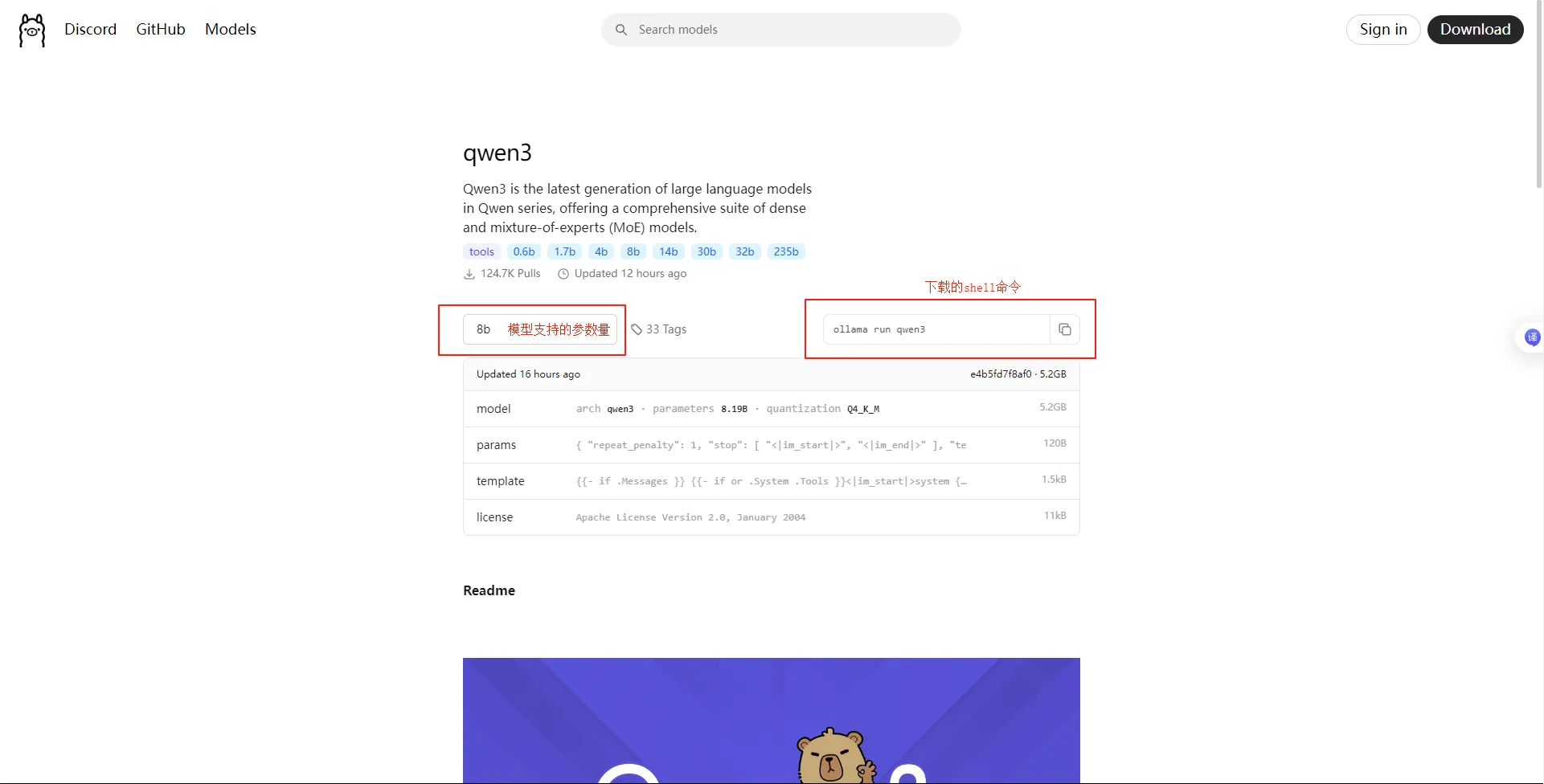
- 选择模型下载:
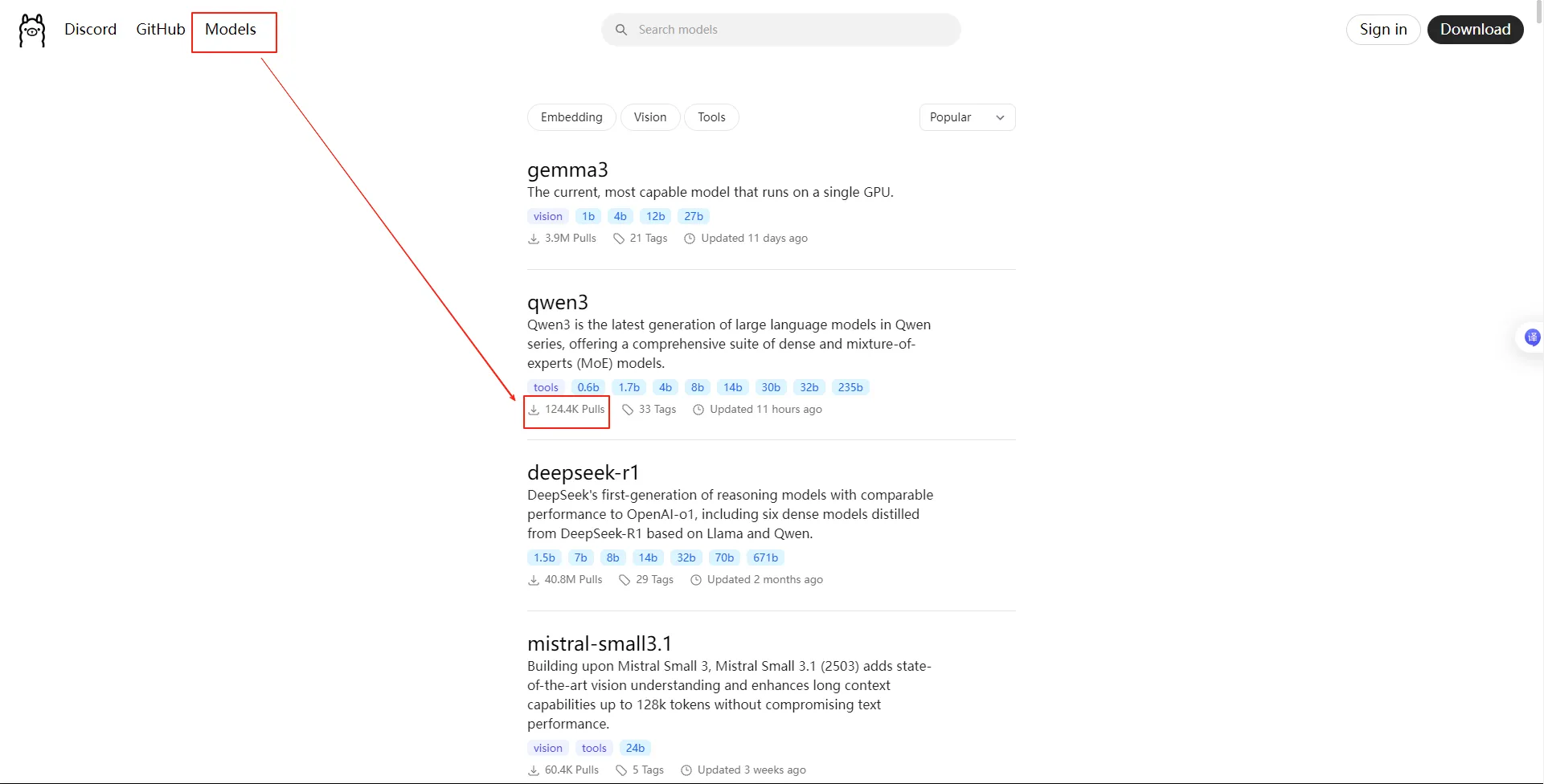
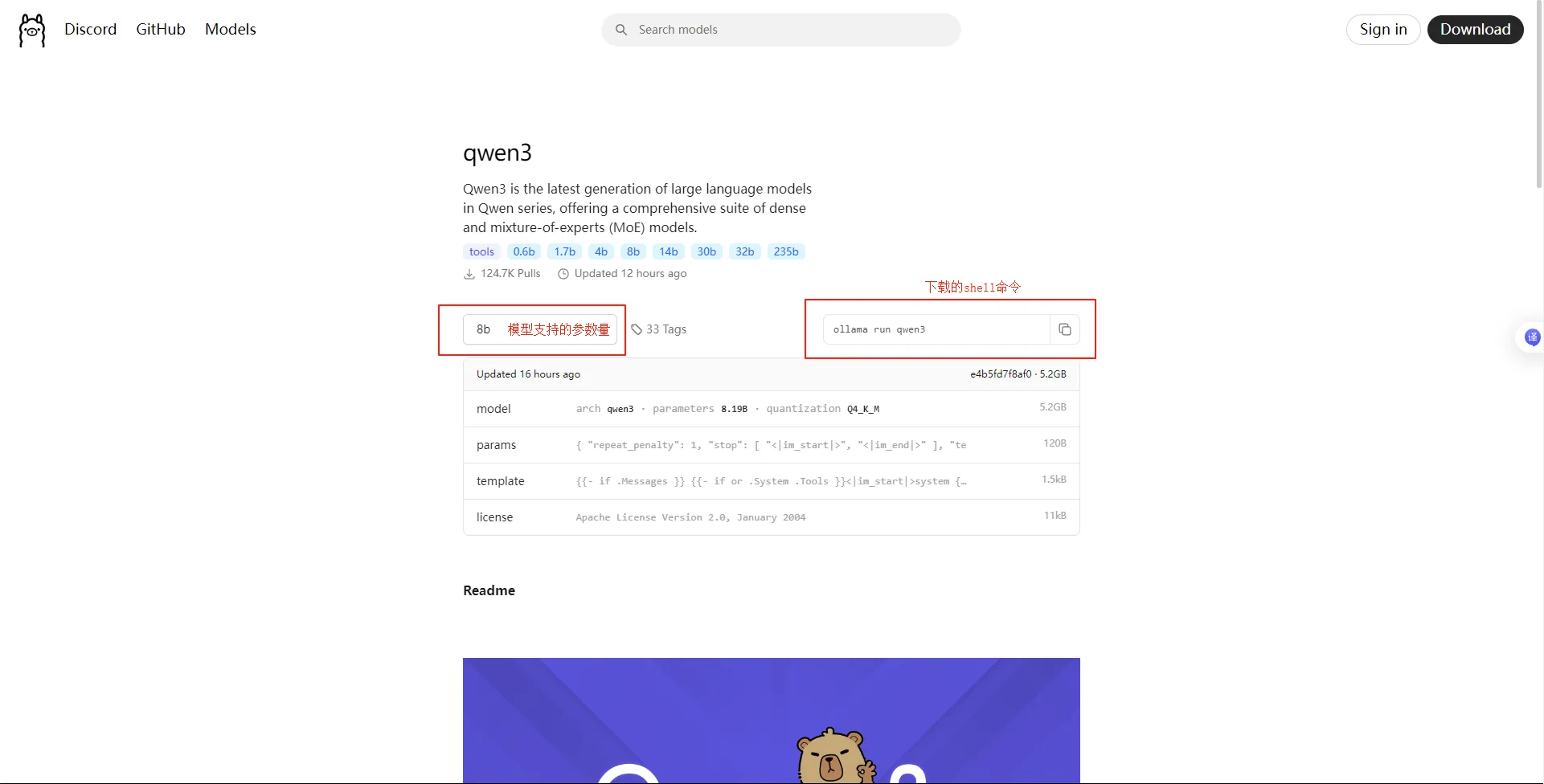
- 选择模型版本(参数越大,能力越强,但所需显卡算力要求大),复制命令到cmd下载:
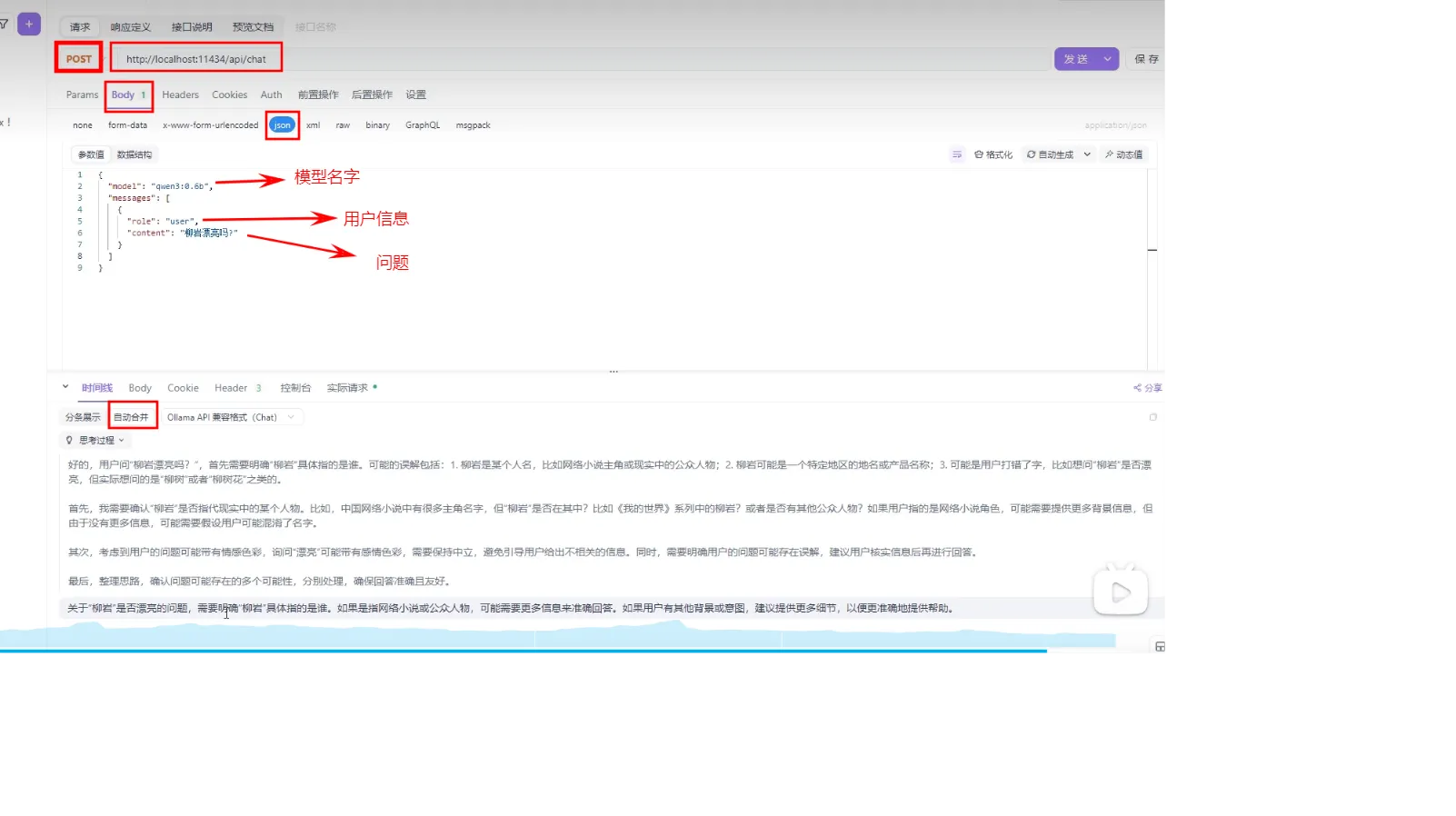
Apifox调用本地部署模型
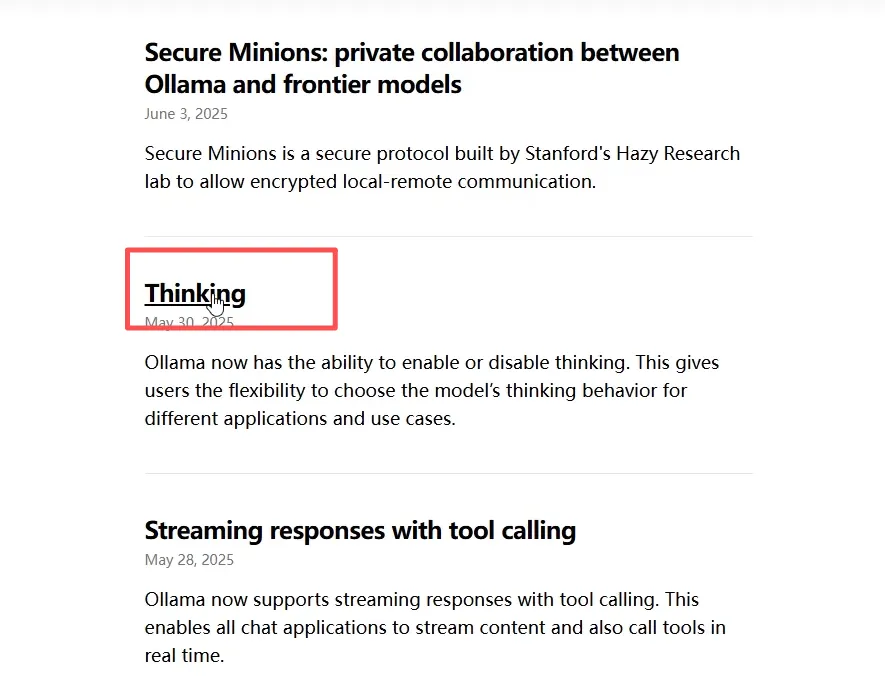
- 在本地成功部署模型后,可进入ollama官网,在此页面往下滑,有个Blog,再点击thinking,继续往下滑,直到出现

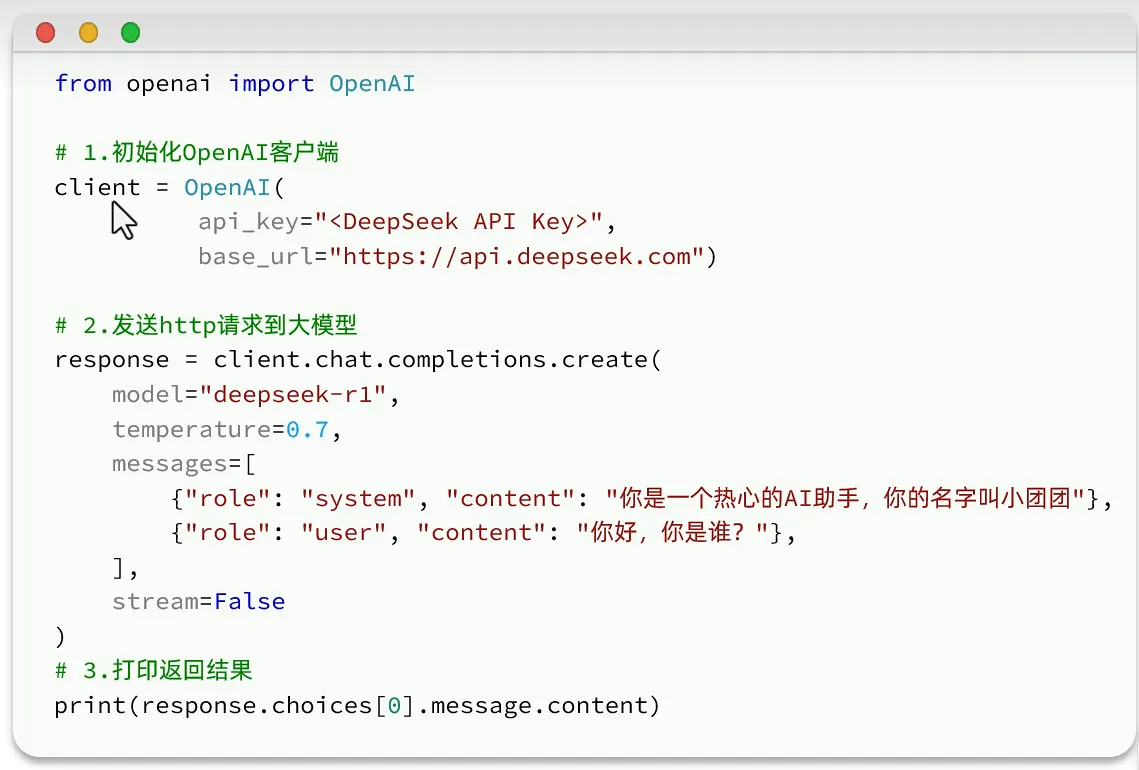
调用大模型
- 遵循openAI规范(引领者)
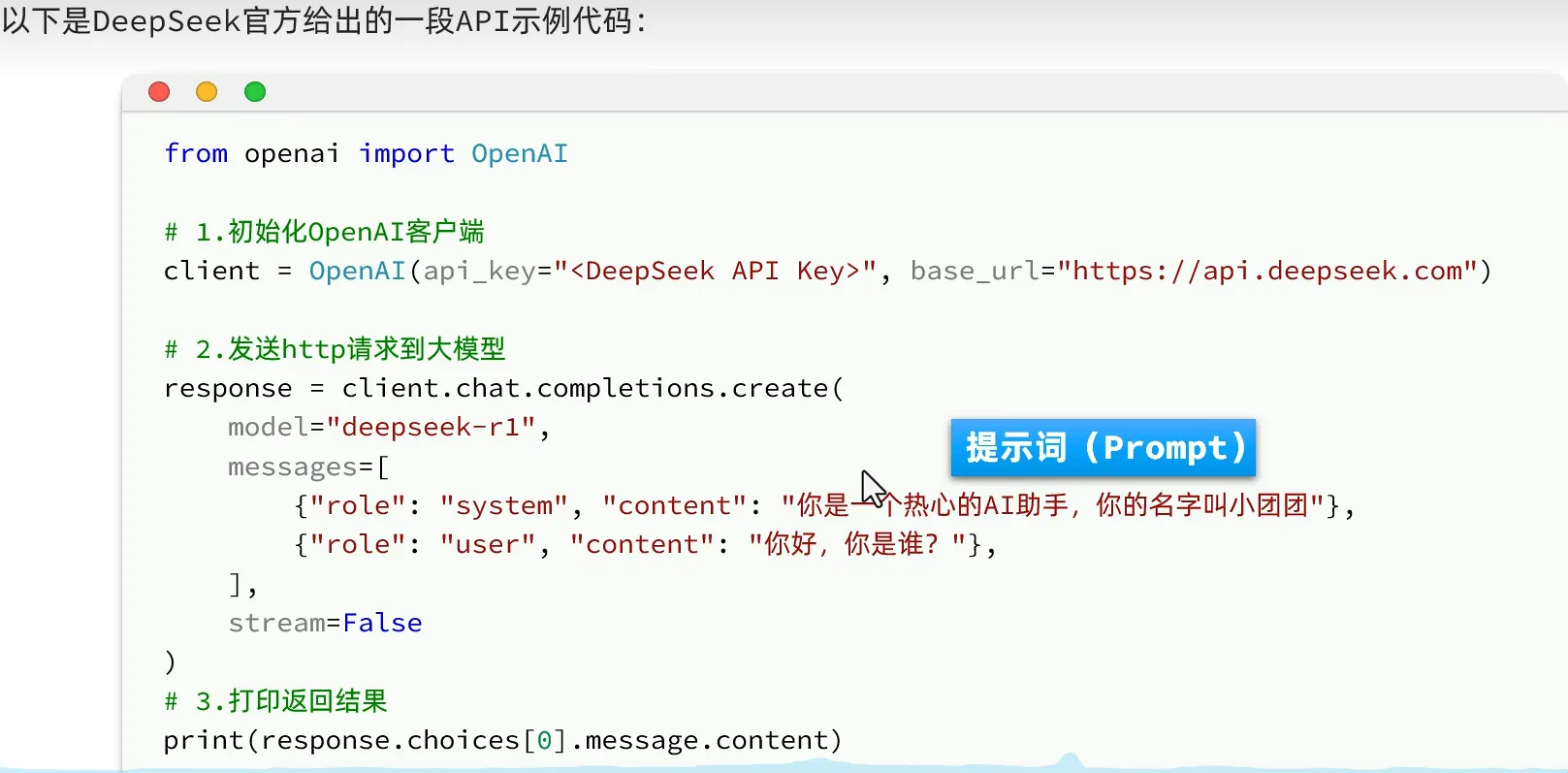
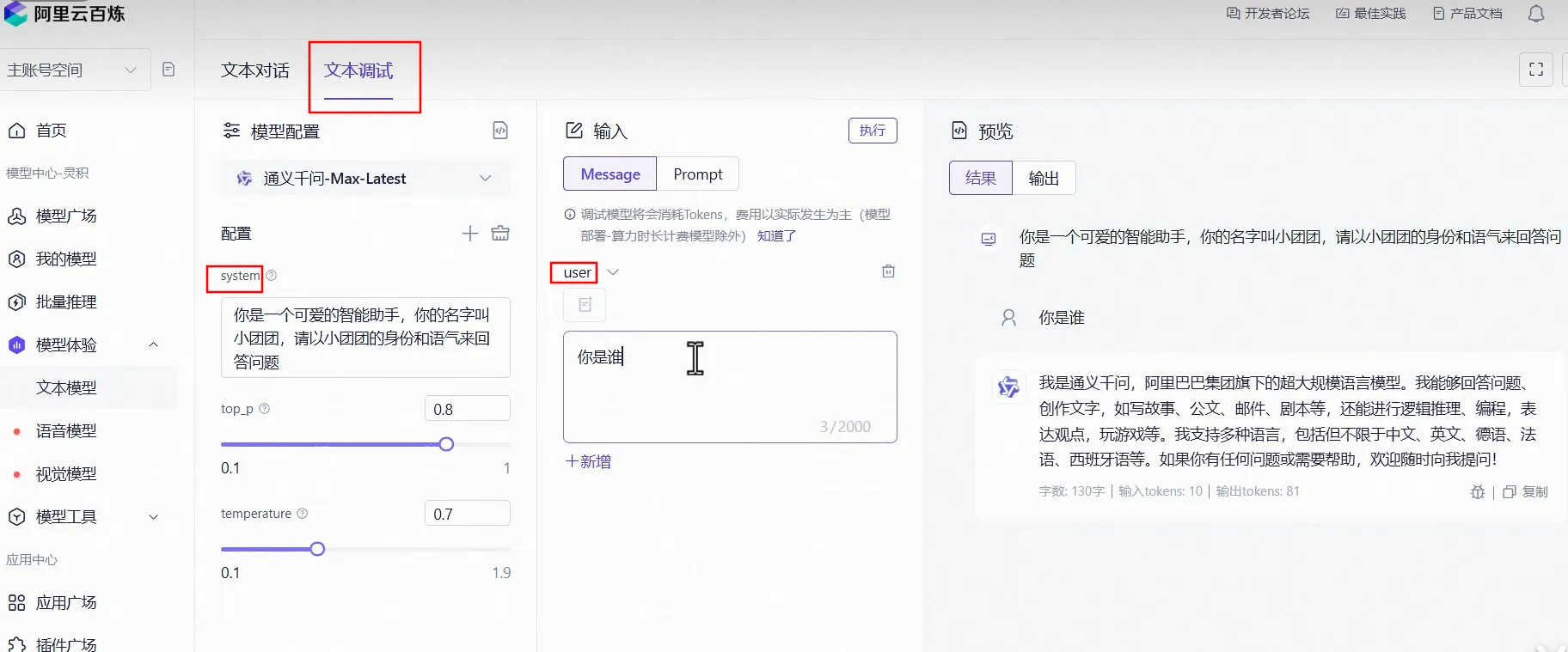
常见参数

响应数据

token是什么
在大语言模型中,Token是大模型处理文本的基本单位,
可以理解为模型“看得懂”的最小文本片段
用户输入的内容都需要转换成token,才能让大模型更好的处理
英文:一个token = 4个字符
中文:一个汉字 ≈ 1~2个token
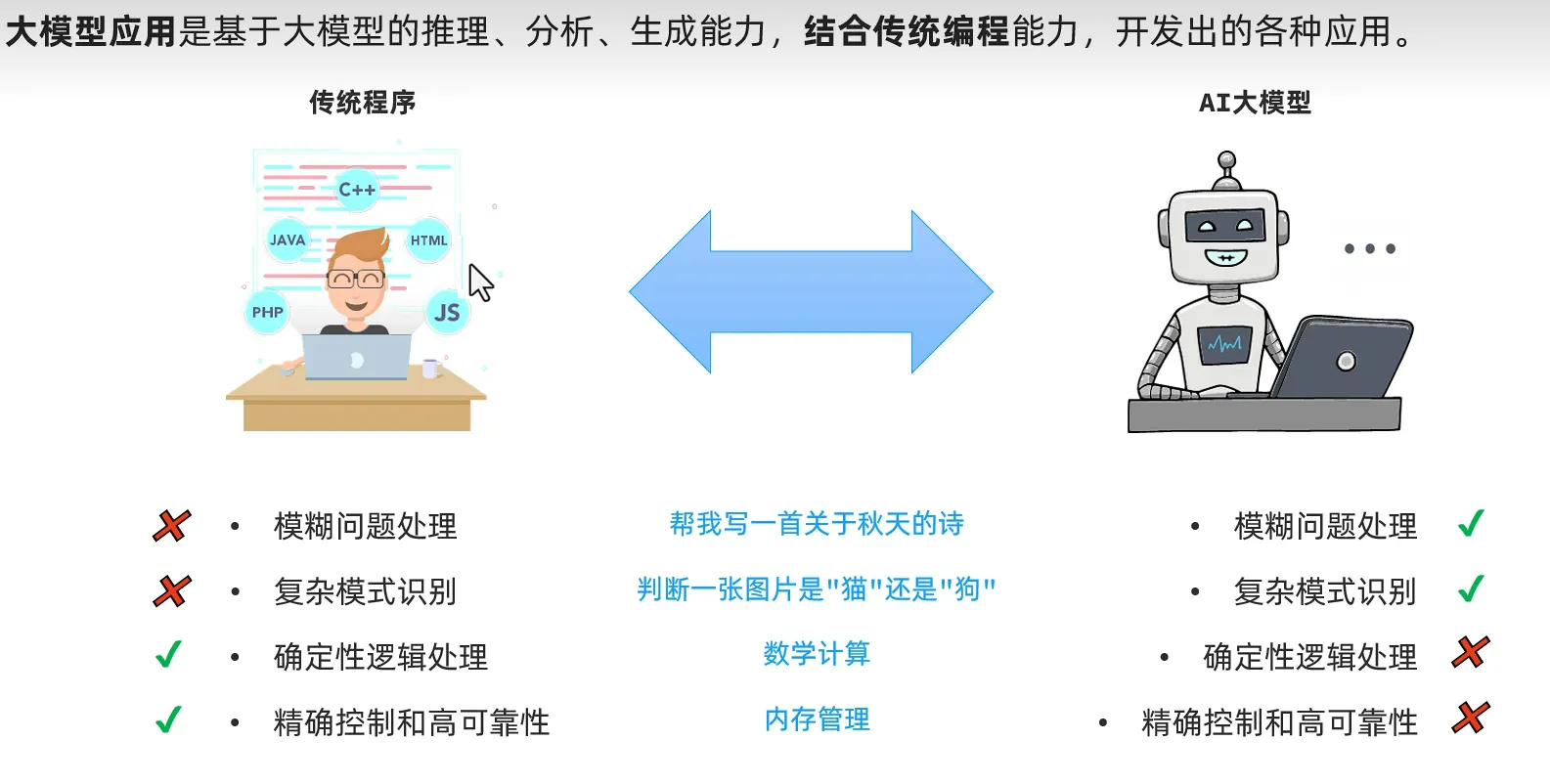
大模型应用
- 注意区分产品(网页端对话的那种全叫产品)和大模型
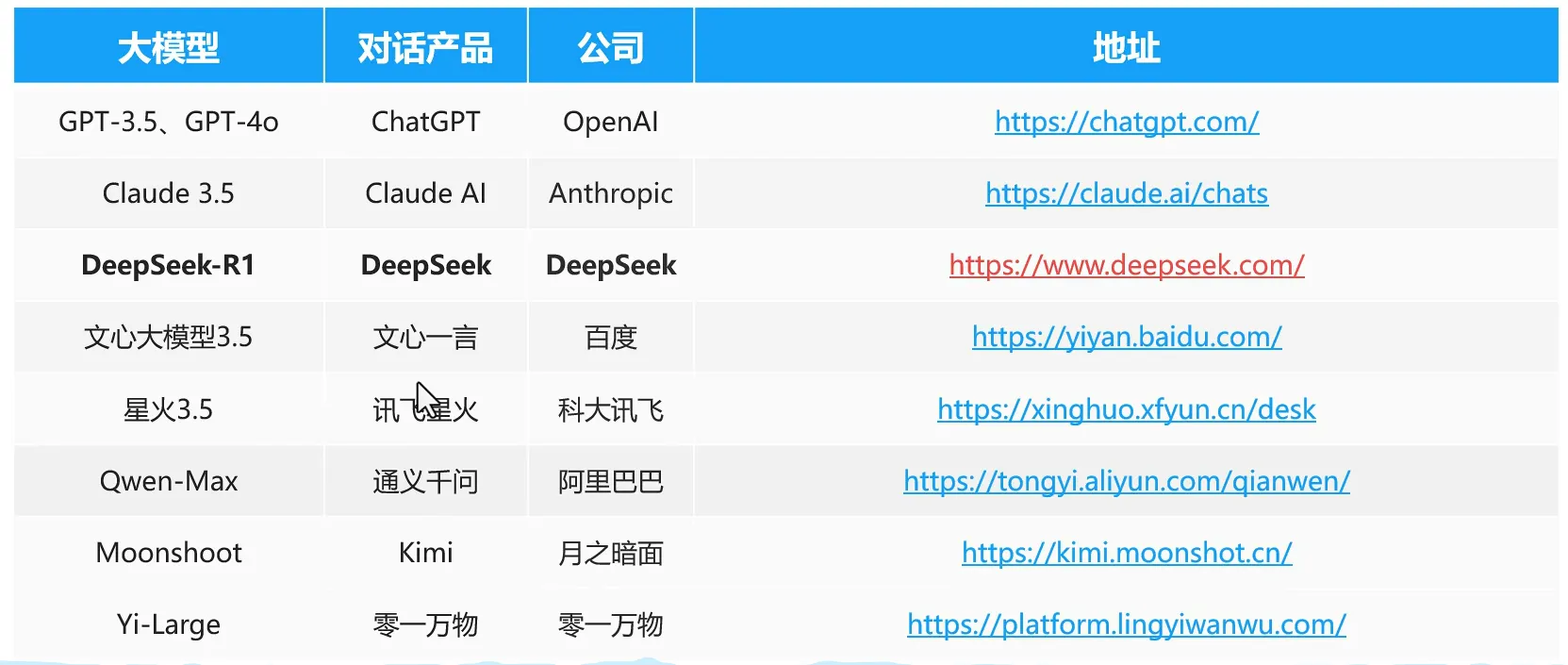
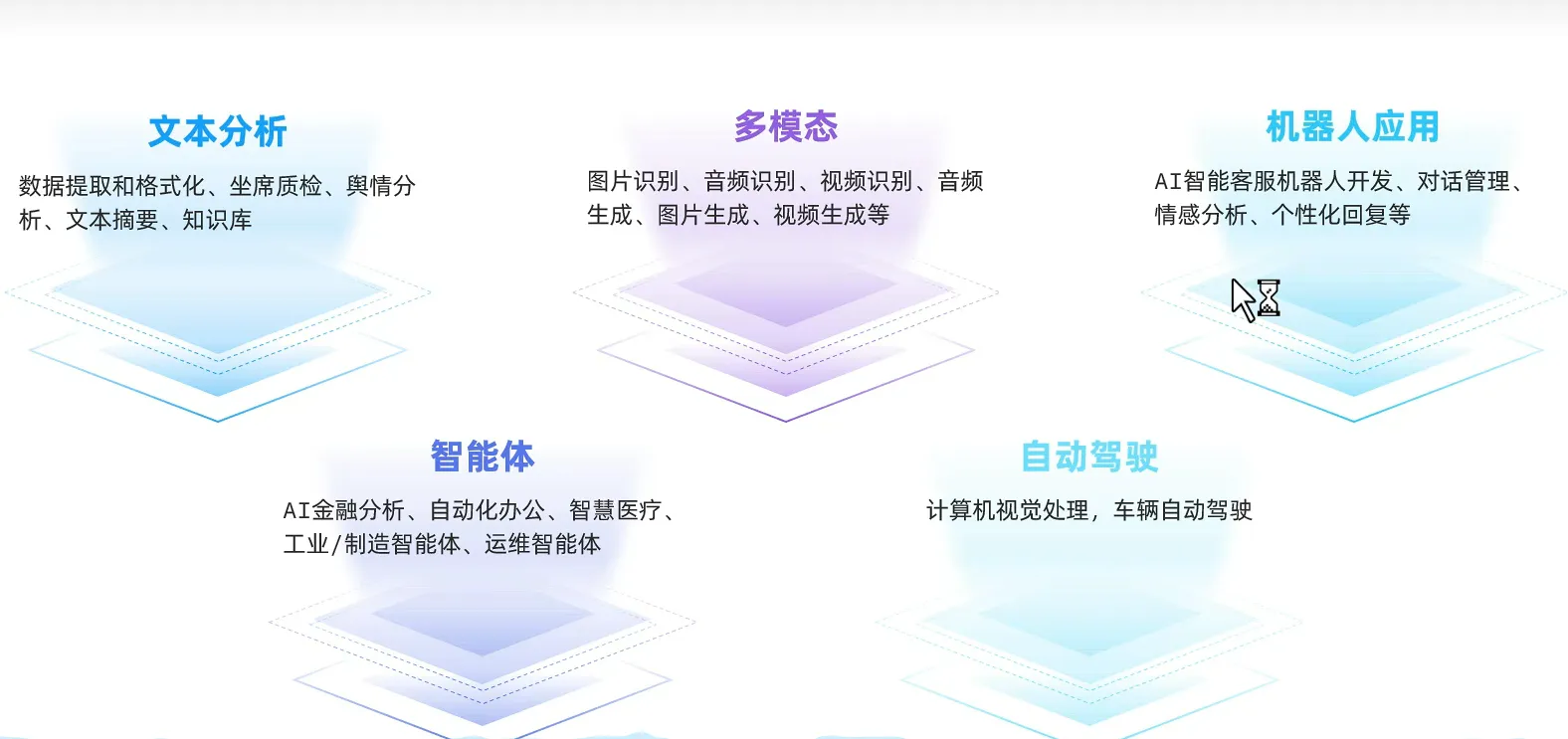
AI应用开发技术架构
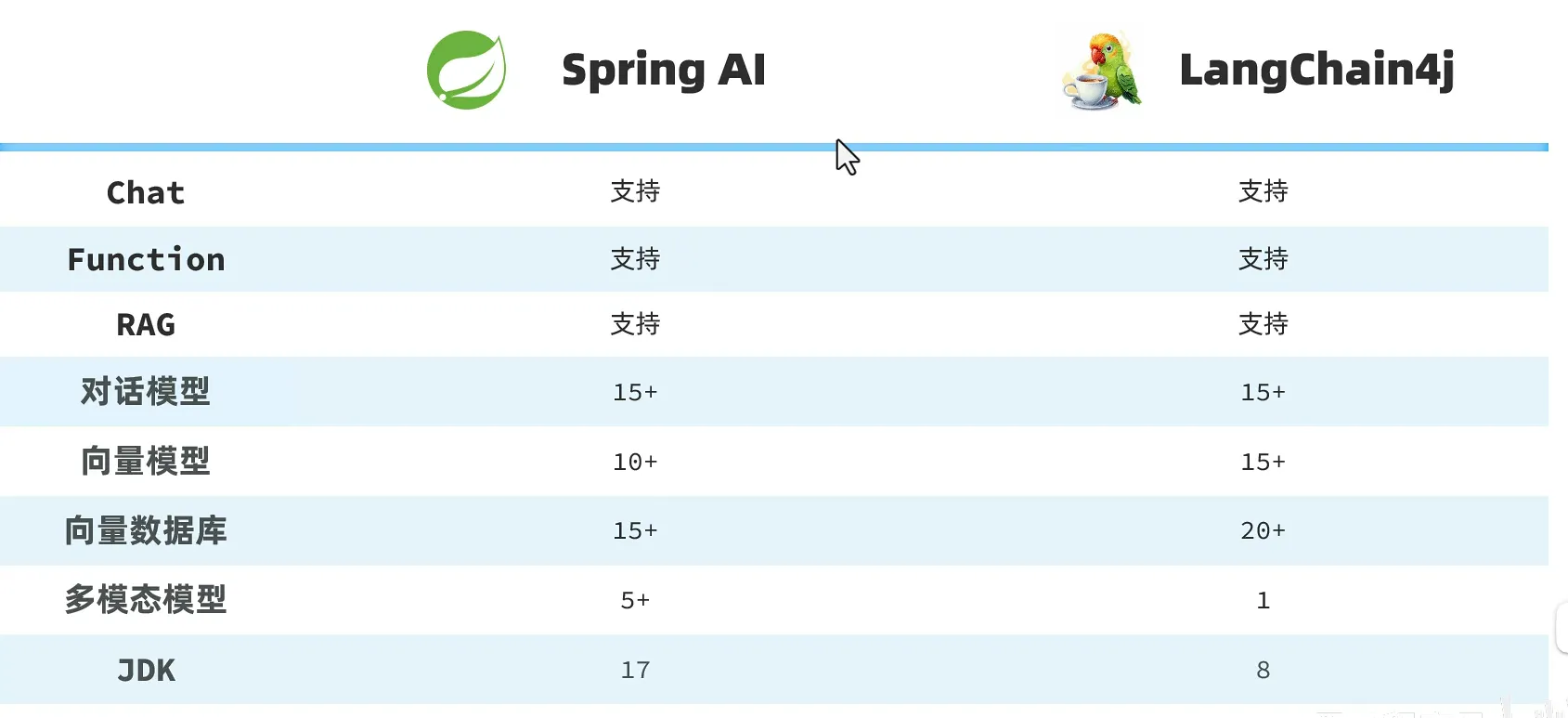
SpringAI
- 新项目推荐springAI,老项目推荐LangChain4j
对话机器人
- openAI访问大模型的规范
操作步骤
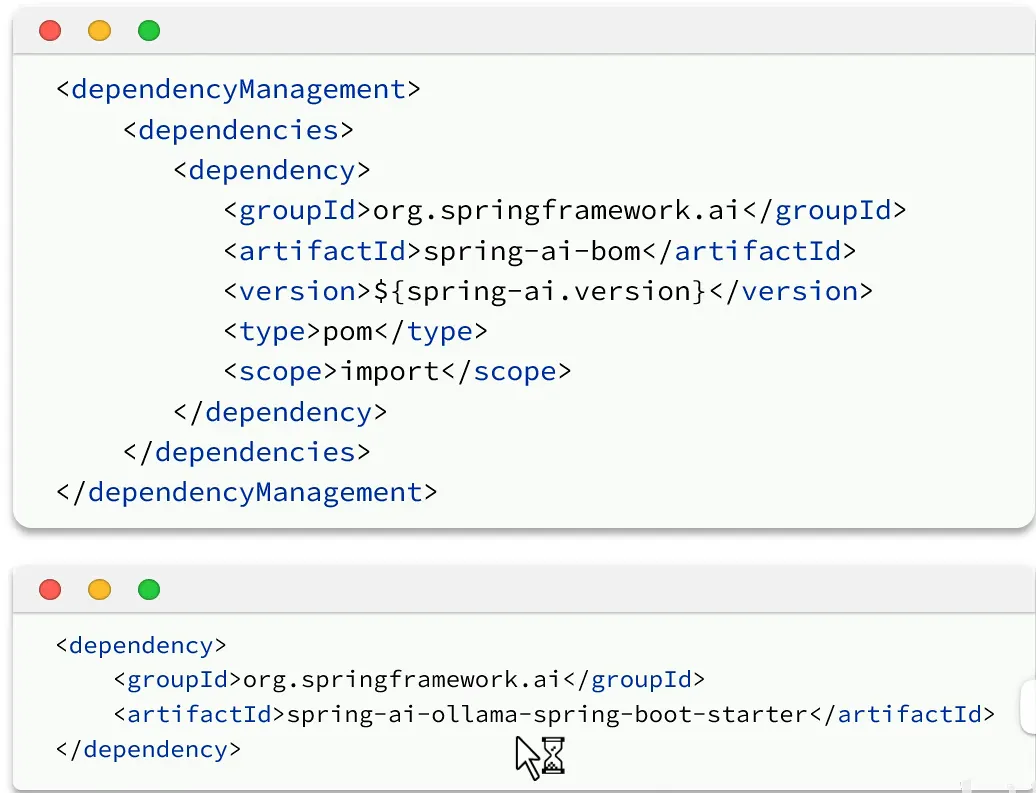
- 引入依赖
- 引入管理依赖:管理与springAI有关的所有依赖以及指定版本
- 引入(基于ollama)模型起步依赖
- 配置模型
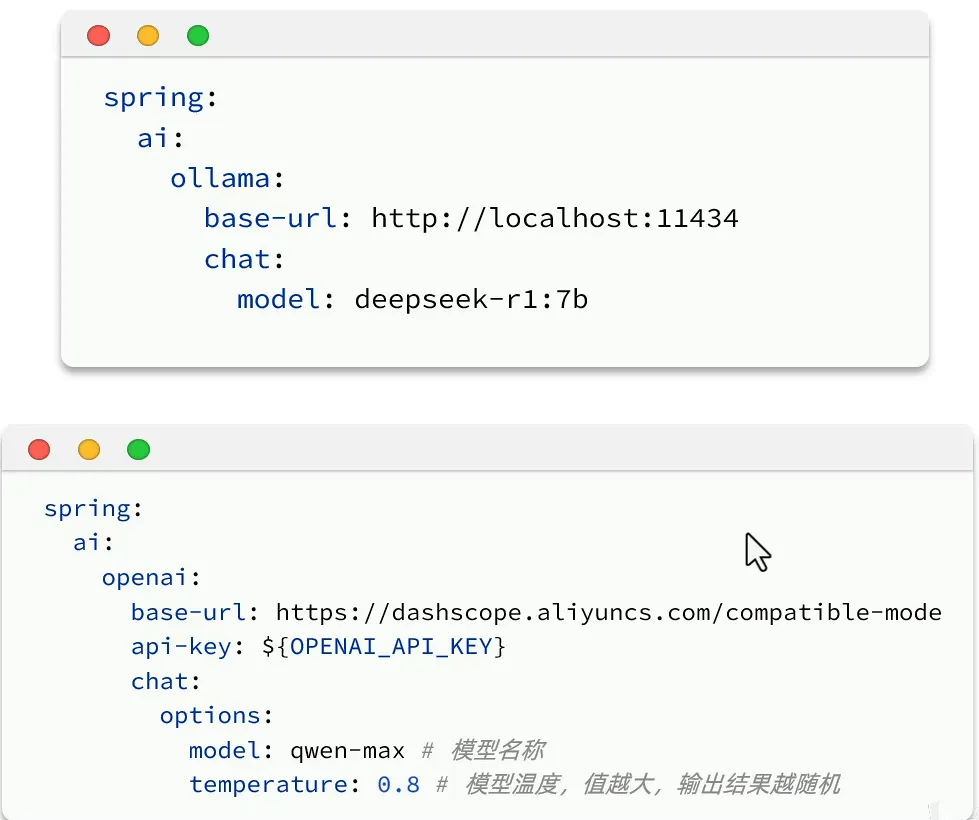
- 基于ollama
- 基于openAI
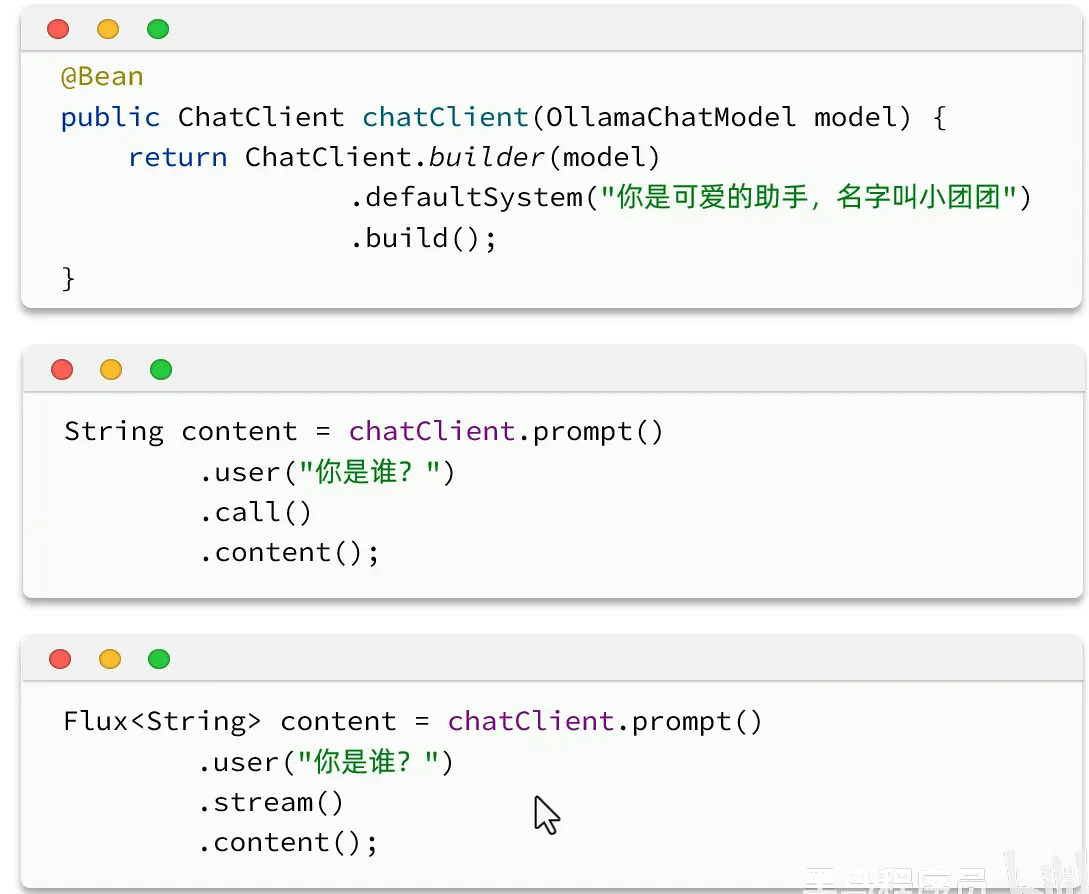
- 配置客户端
实例
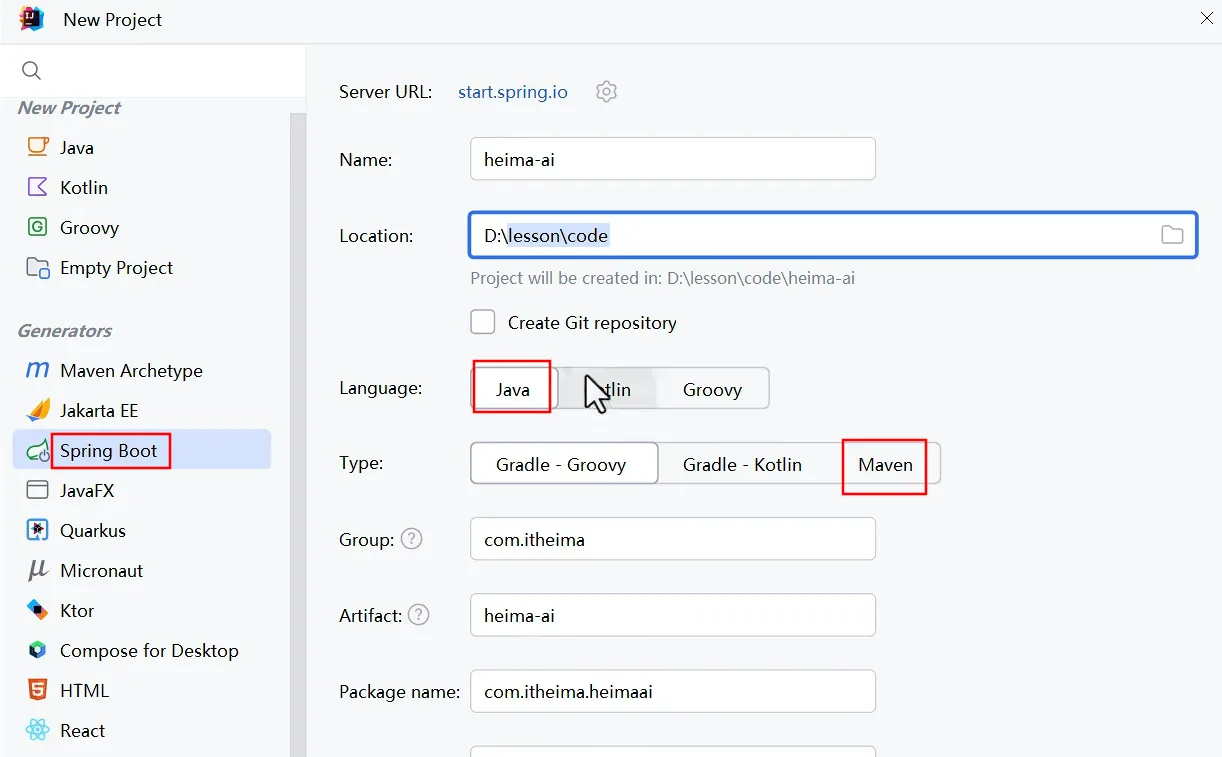
- 新建项目(利用脚手架快速搭建)
- 引依赖
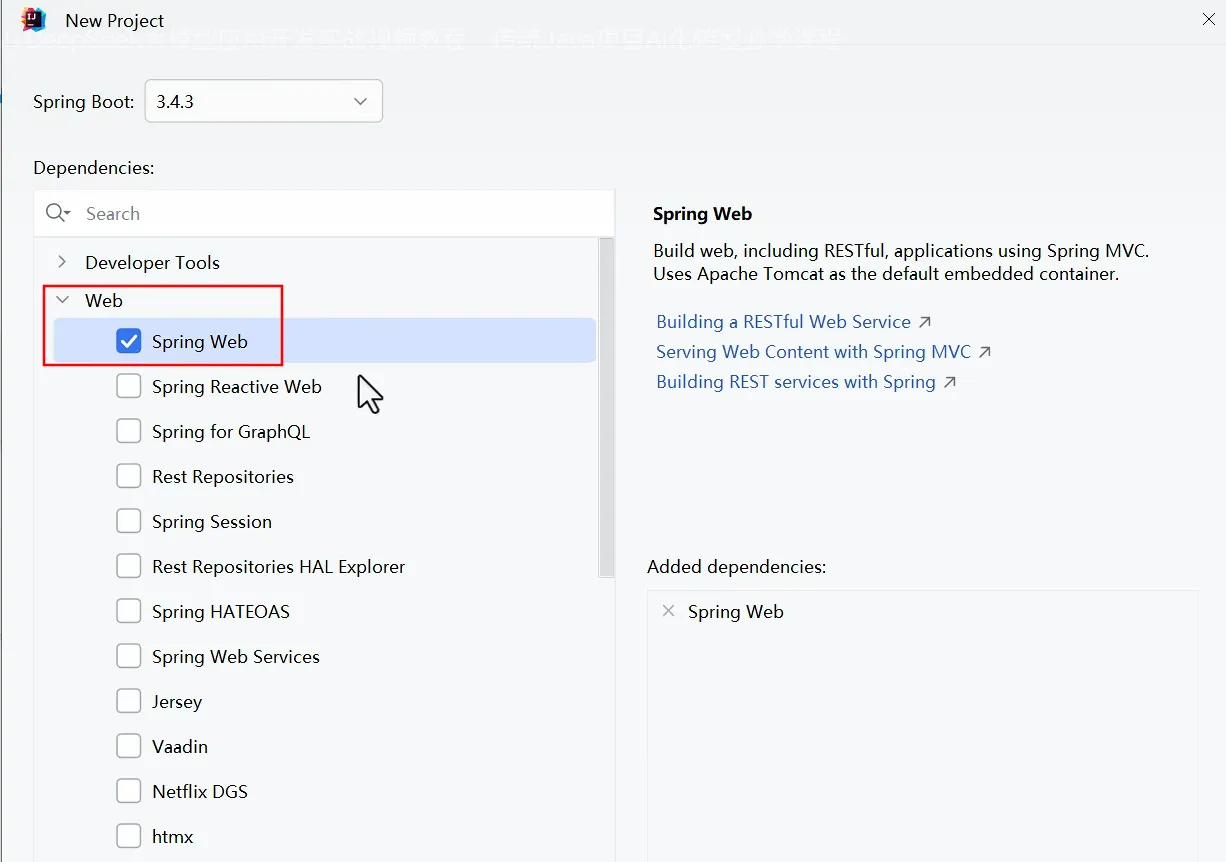
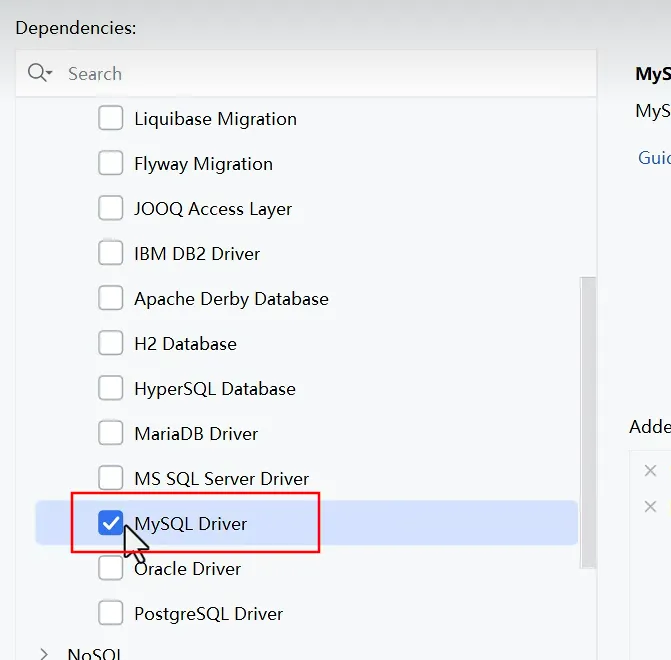
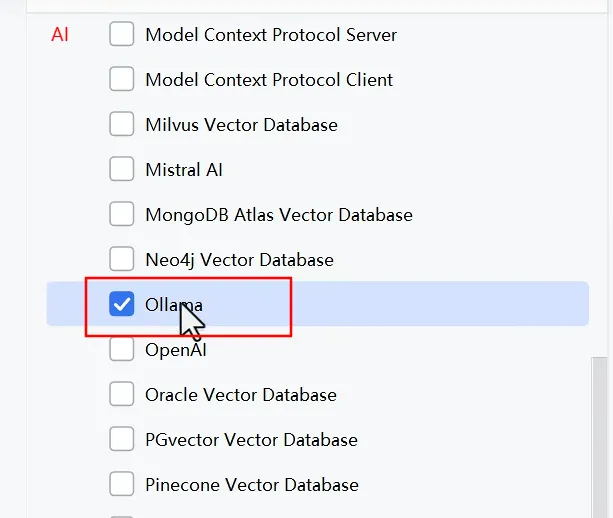
- 配置模型
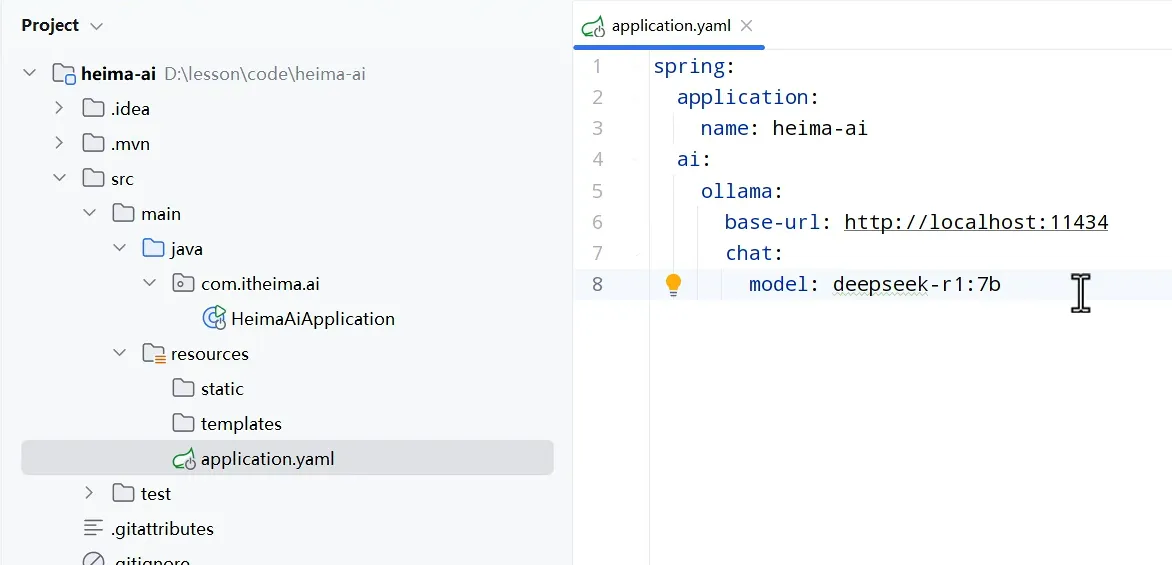
- 配置客户端
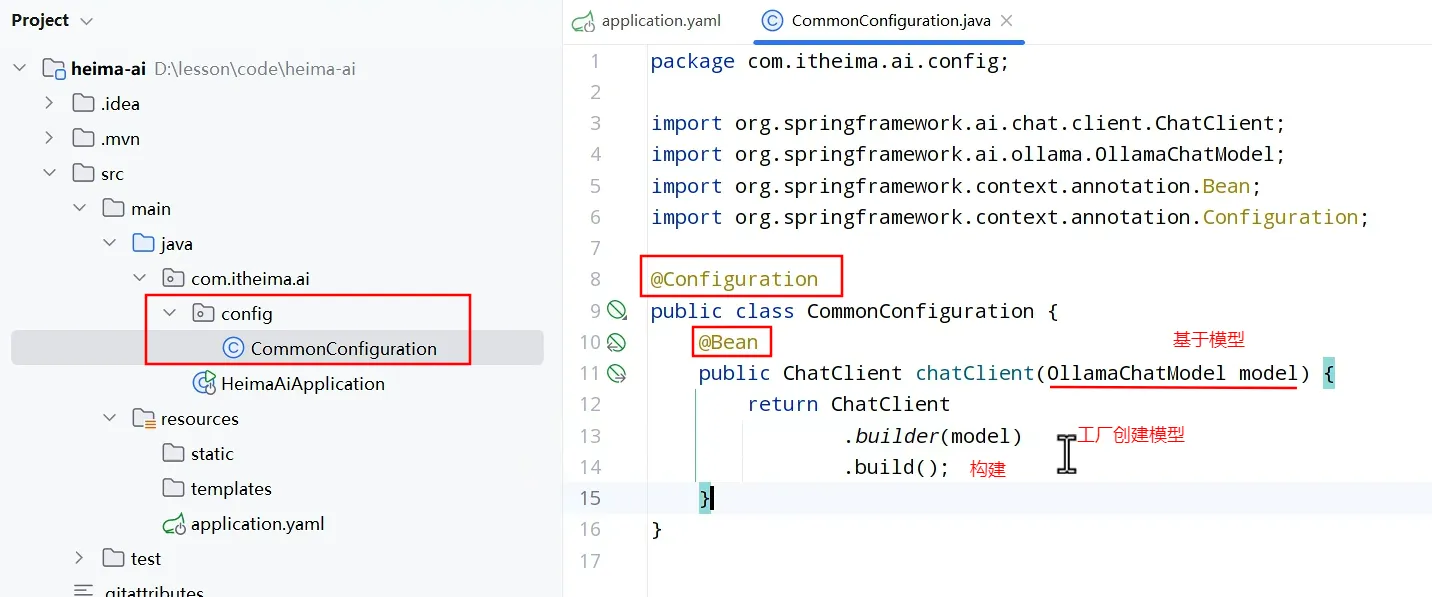

- 使用
- 整段生成再输出
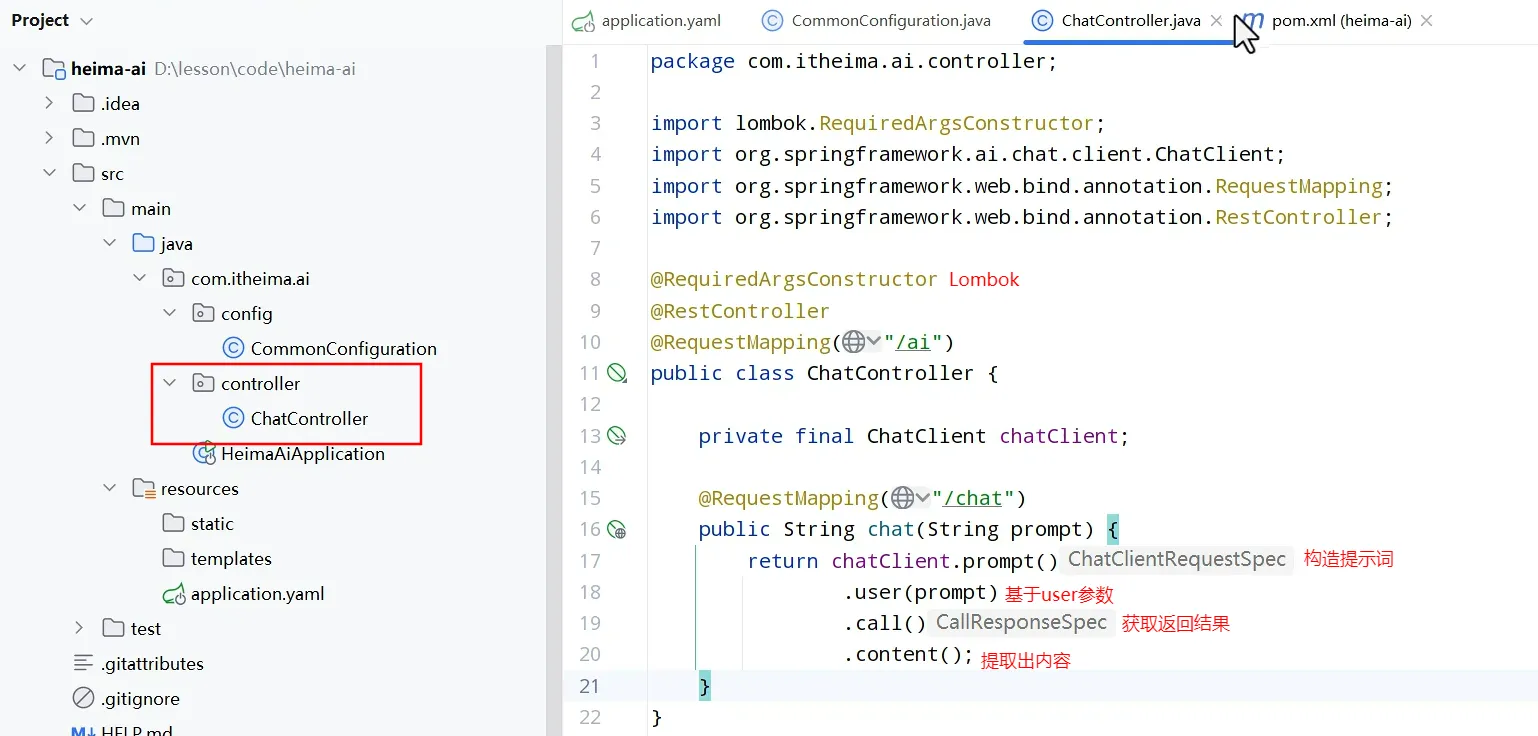
2. 流式输出Flux对象
会话日志
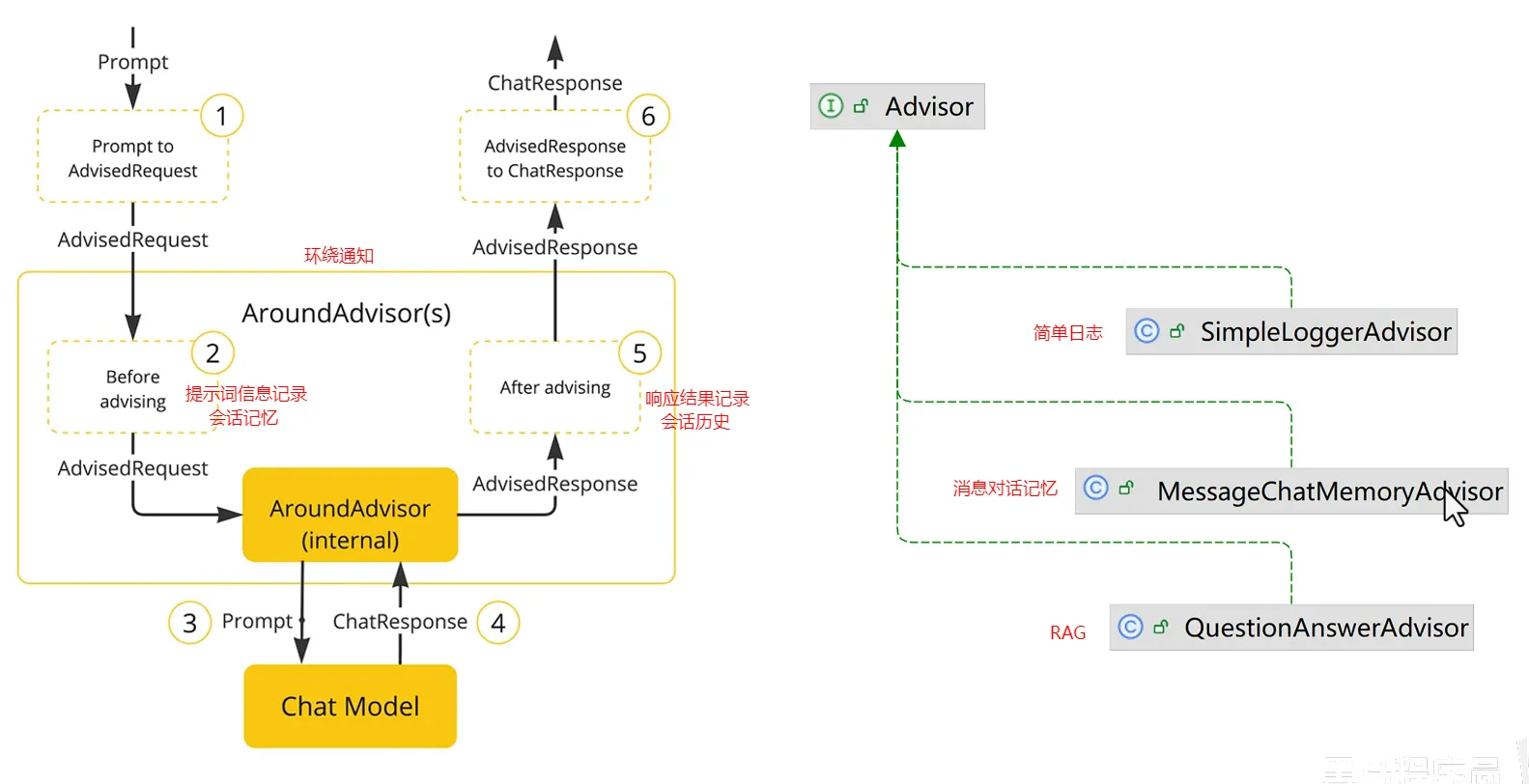
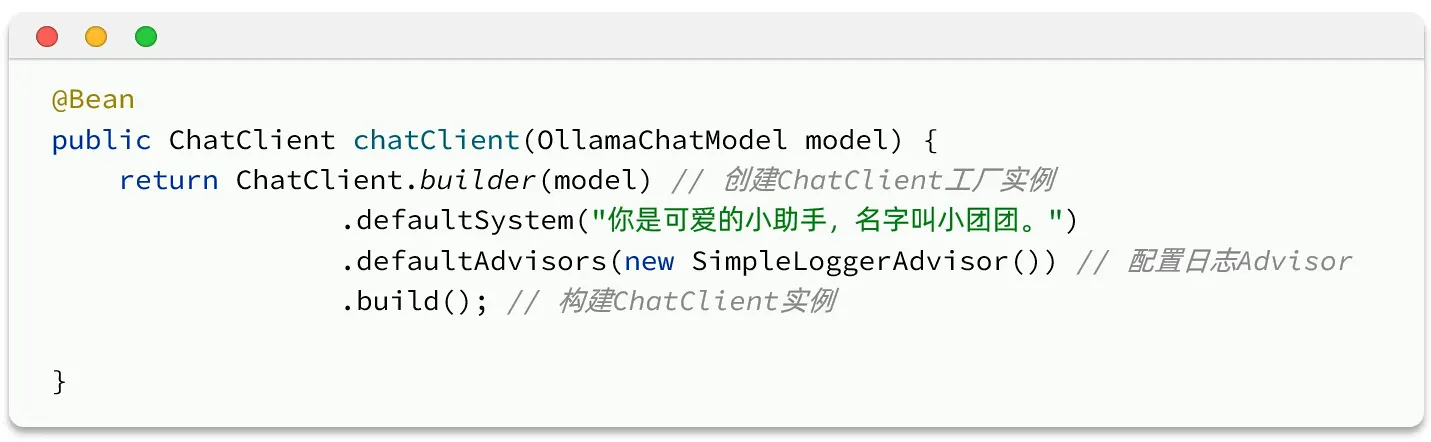
- SpringAI利用AOP原理提供了AI会话时的拦截、增强等功能,也就是Advisor。
- spring中已经封装好了各种Advisor
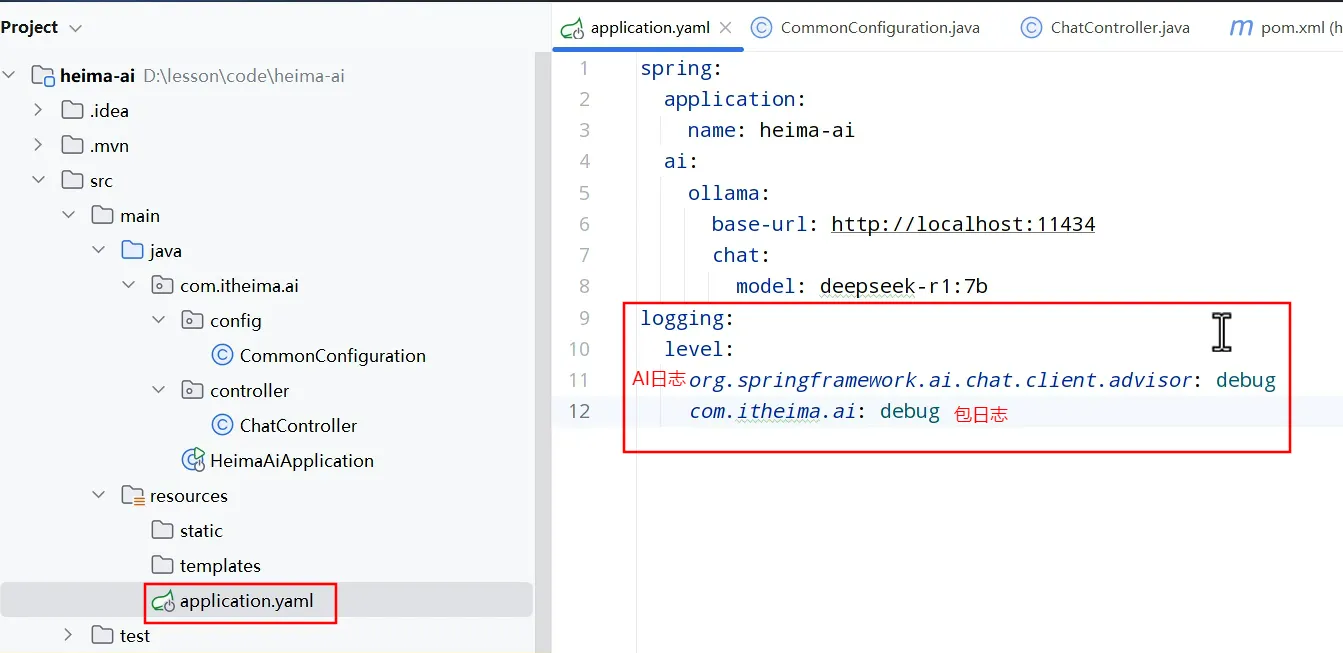
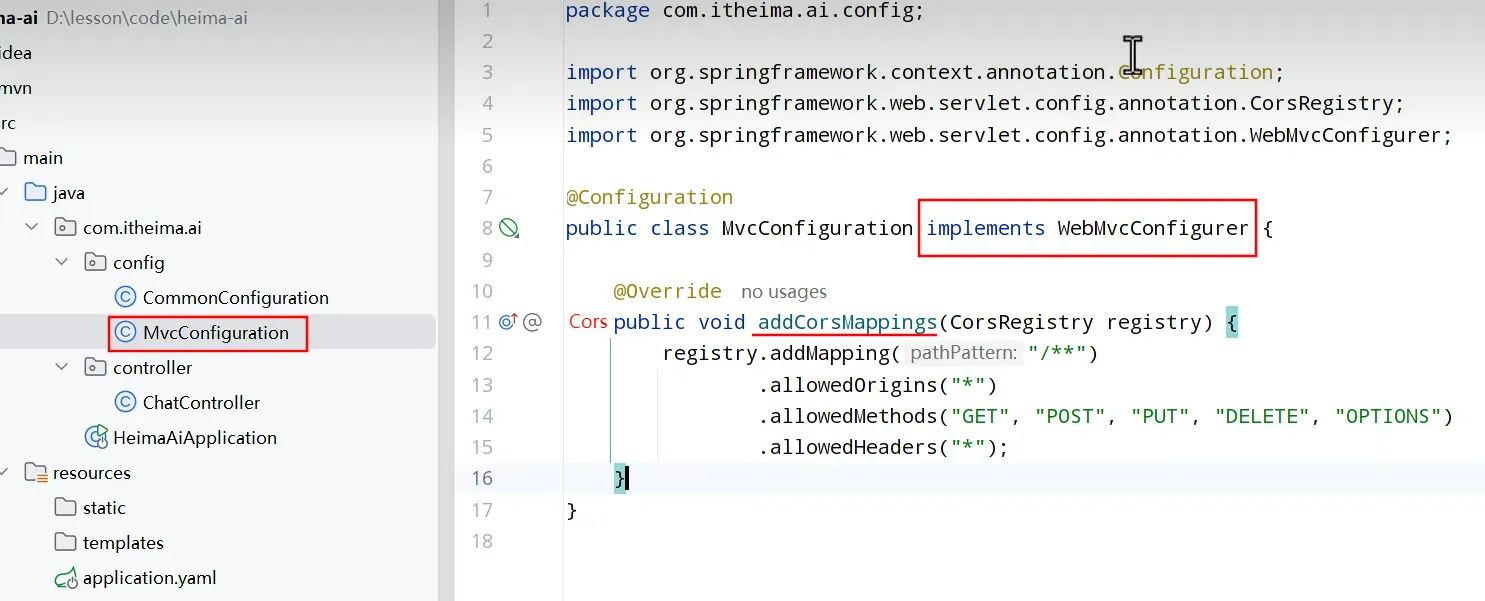
跨域
会话记忆
- 大模型是不具备记忆能力的,要想让大模型记住之前聊天的内容,唯一的办法就是把之前聊天的内容与新的提示词一起发给大模型。
LangChain4j
会话功能
快速入门
- 引入Langchain4j依赖
- 构建openAiChatModel对象
- 调用chat方法与大模型交互
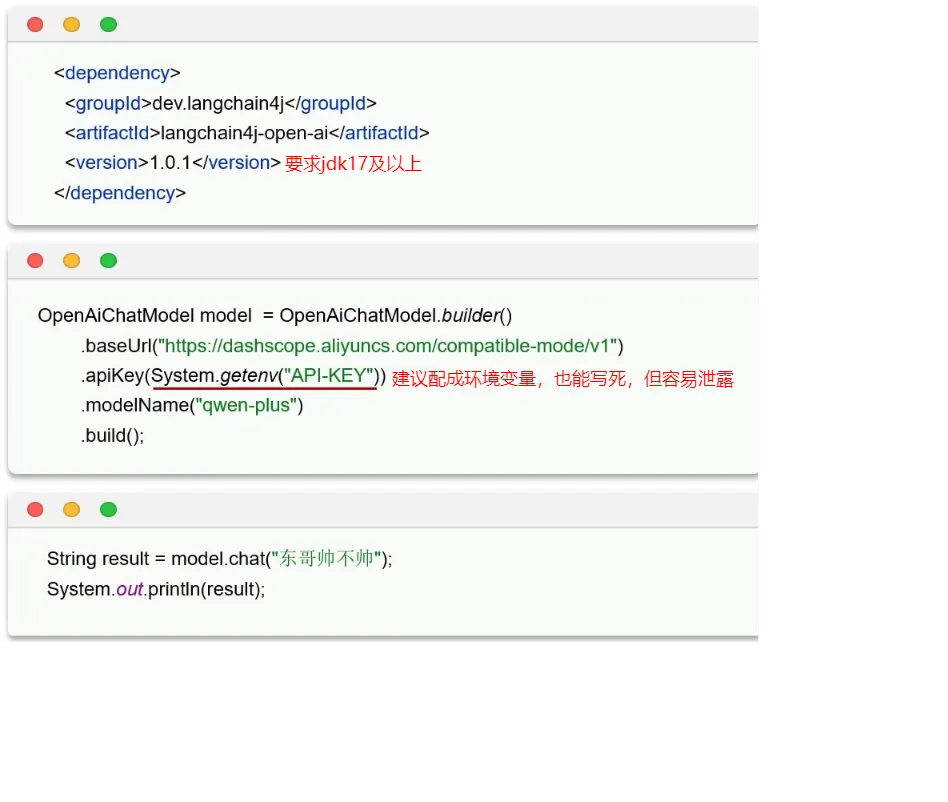
- baseUrl获取:
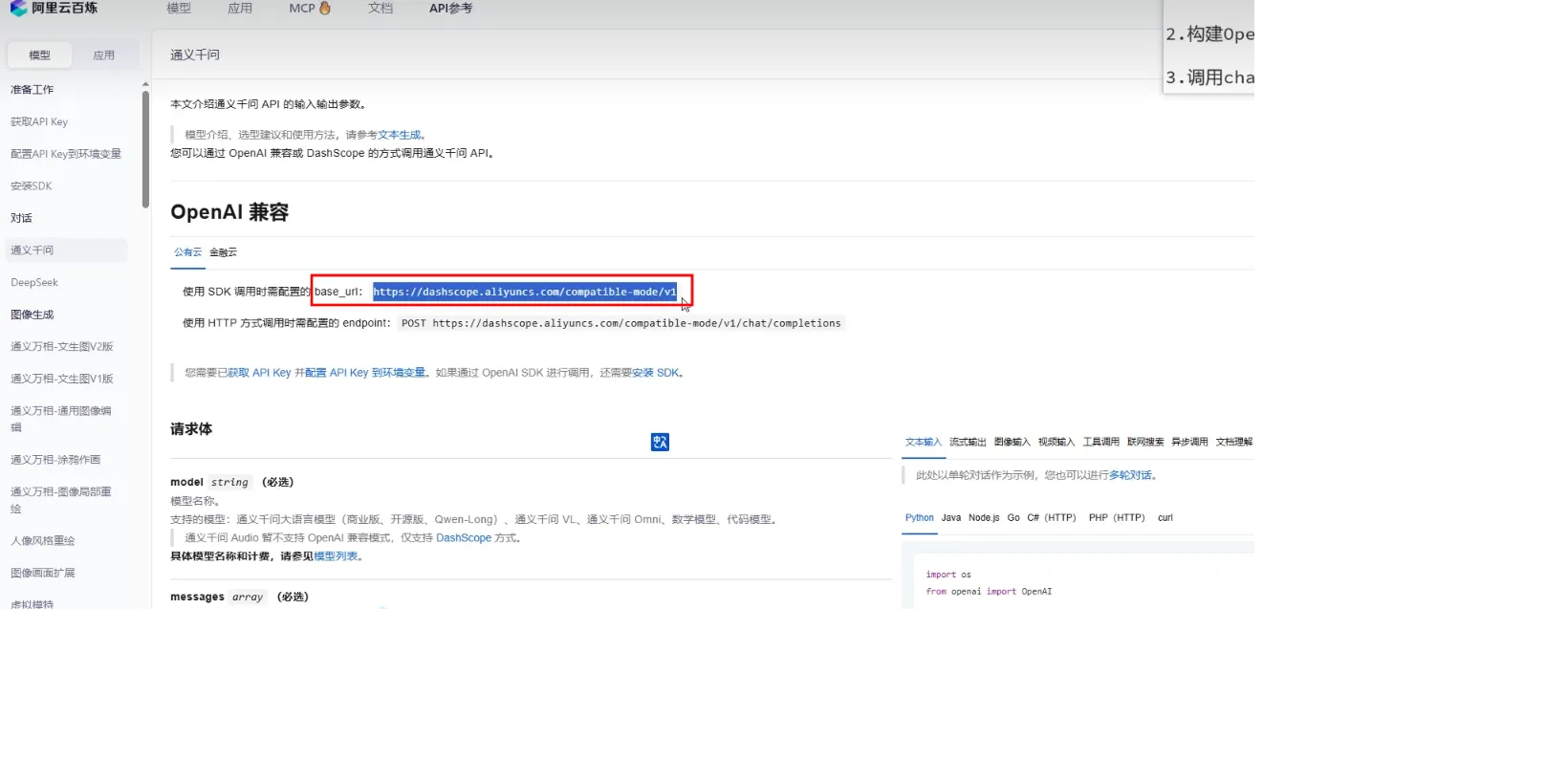
- 配了API KEY后一定要重启idea,因为还没生效,idea启动默认会读一次系统环境变量
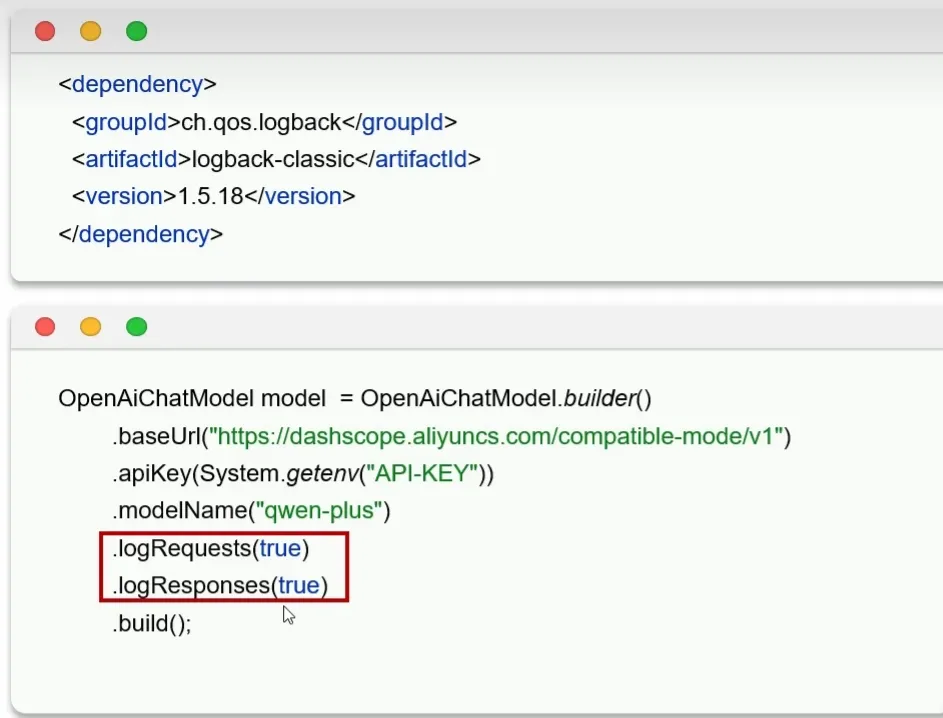
打印日志信息
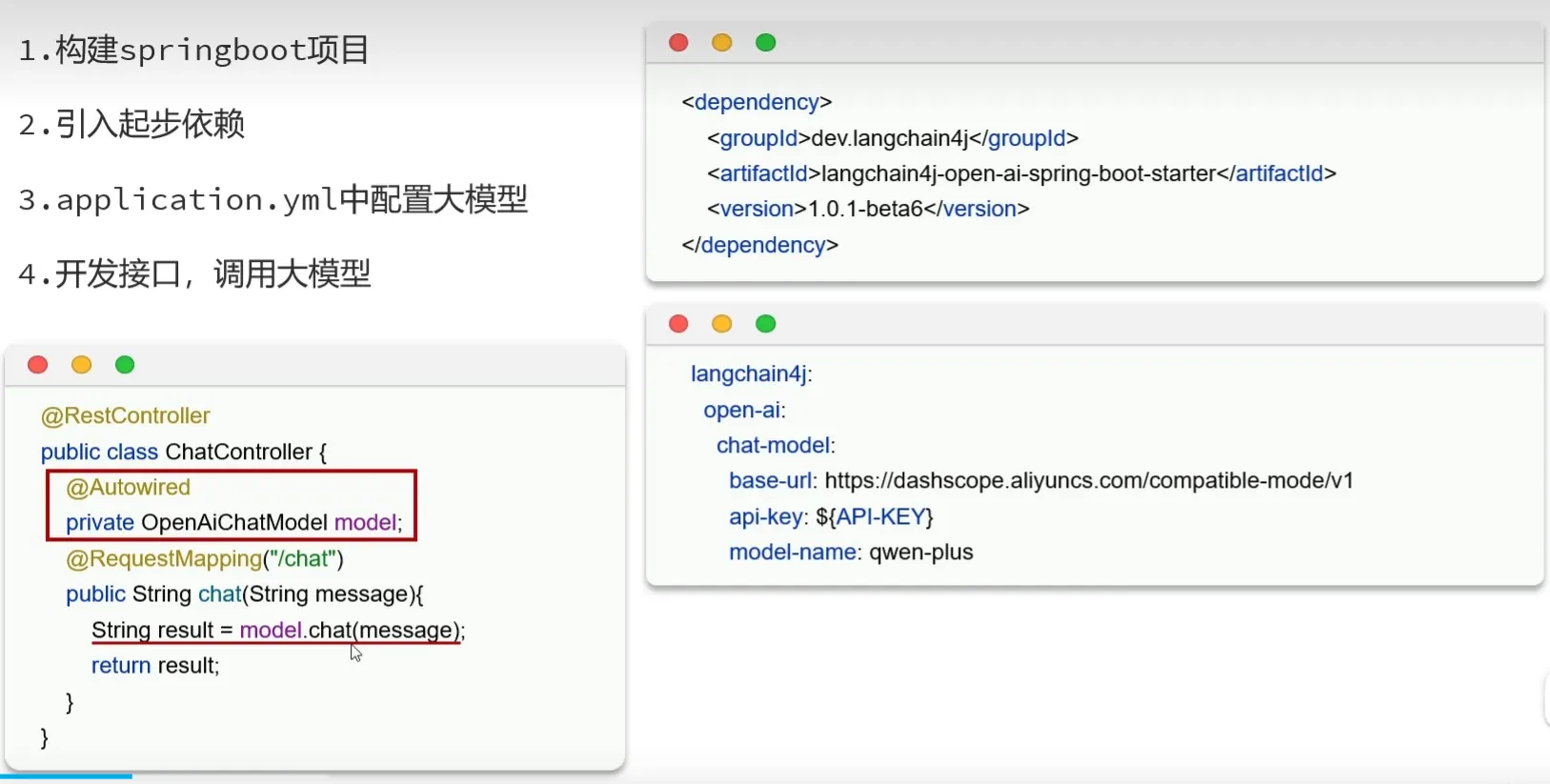
Spring整合LangChain4j
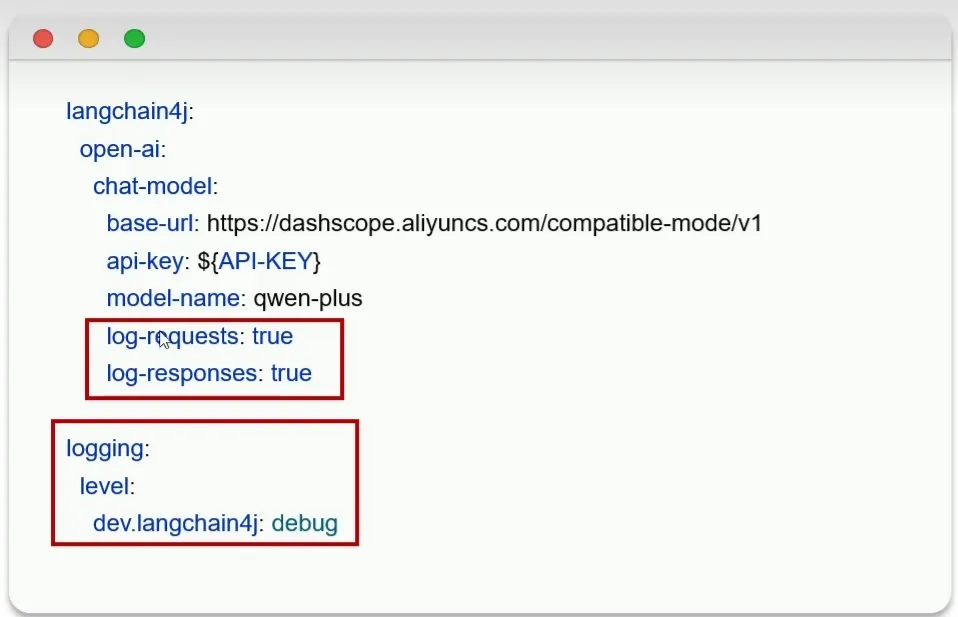
打印日志信息
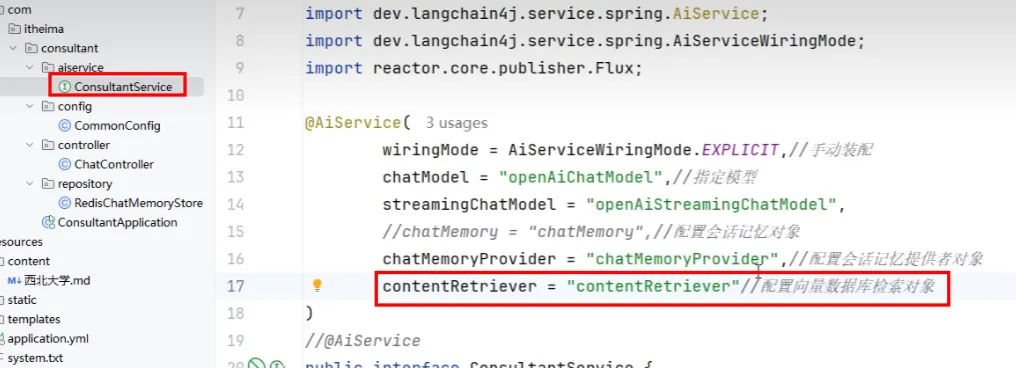
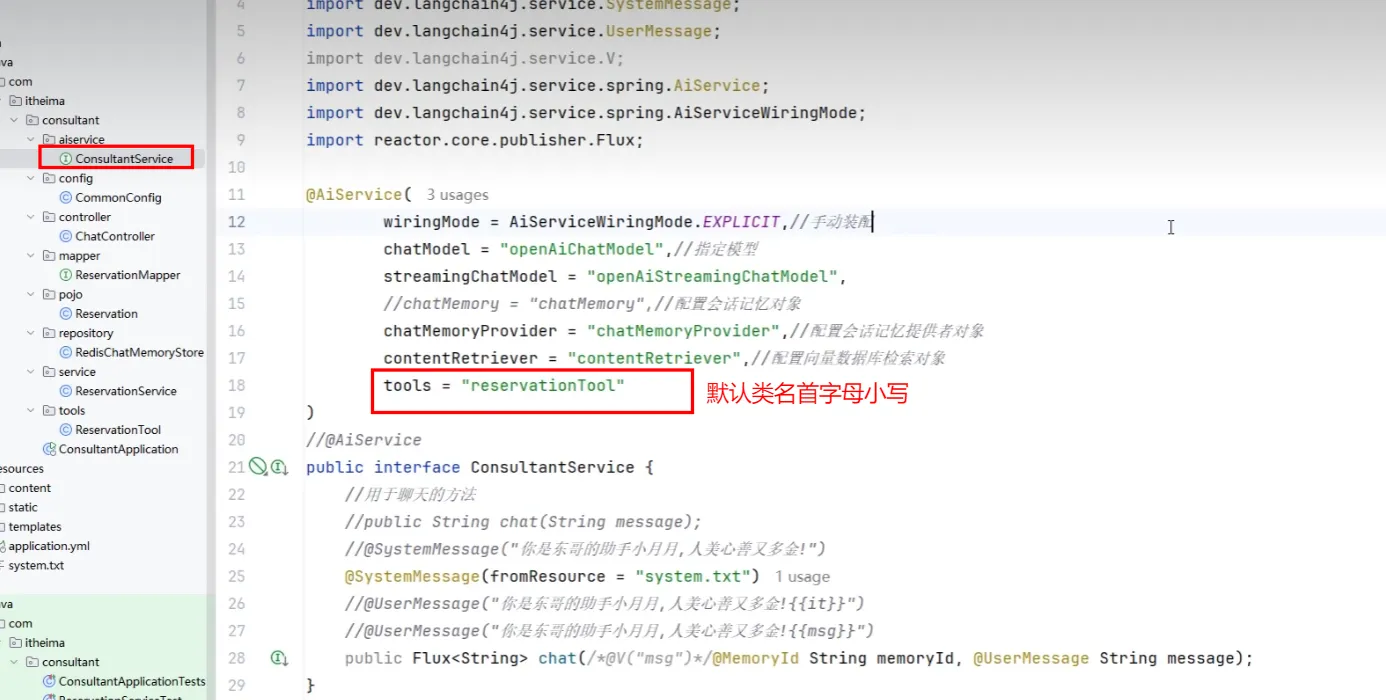
AiServices工具类
- 传统model.chat方法在之后进行会话记忆等功能实现复杂,利用其提供的AiServices工具类更加方便

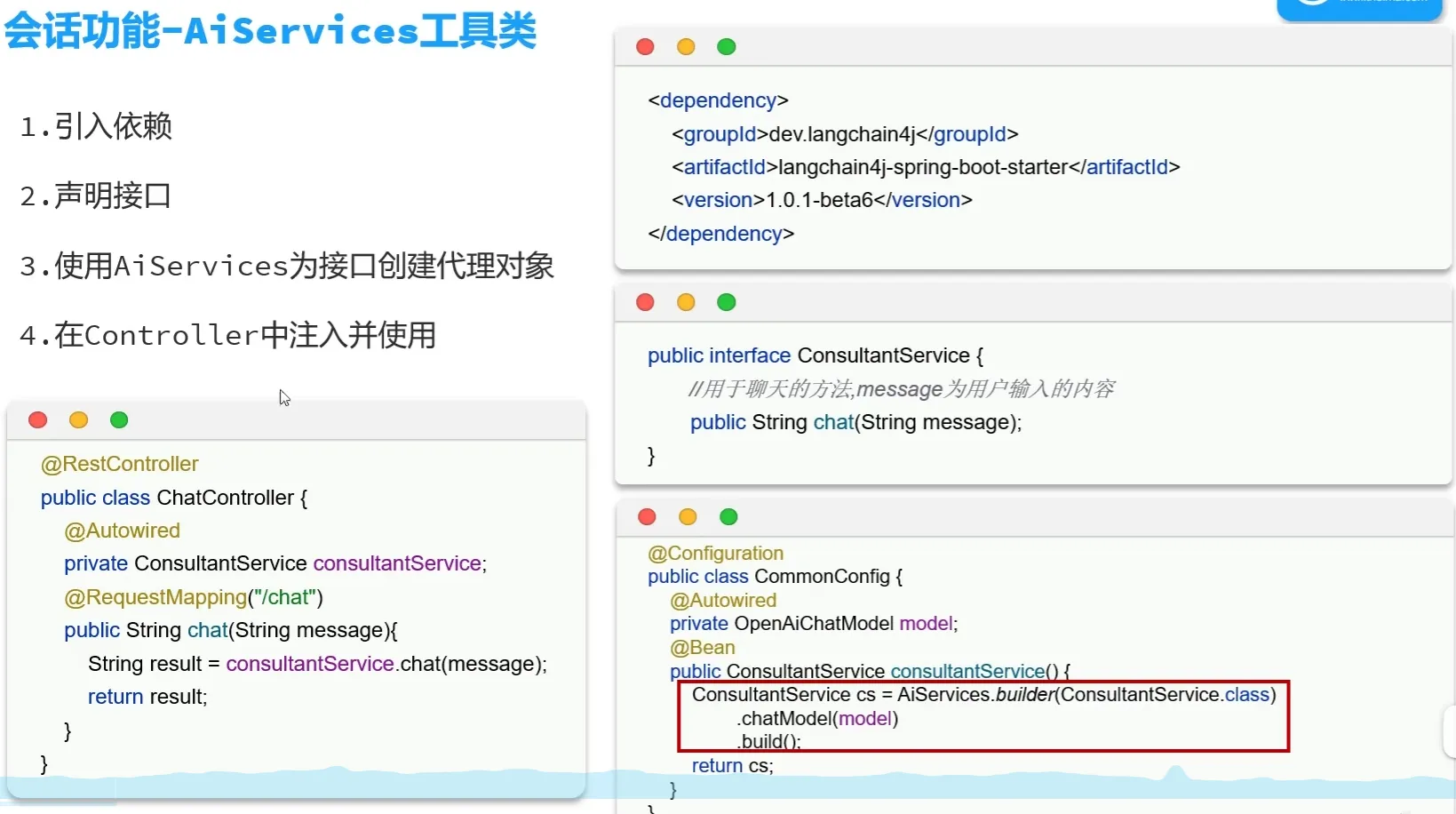
- 声明式使用
- 为接口创建代理对象,并将返回结果注入IOC容器
- wiringModel = AiServiceWiringMode.EXPLICIT,表示创建完代理对象后选择手动装配
- chatModel 表示选择哪个模型,langchain4j默认注入openAiChatModel

- 当然也可以不添加值,会默认自动装配
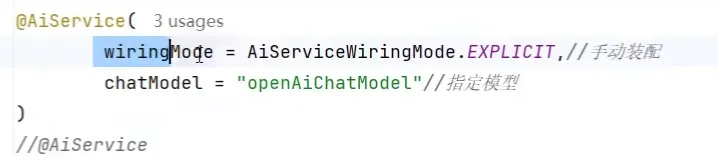
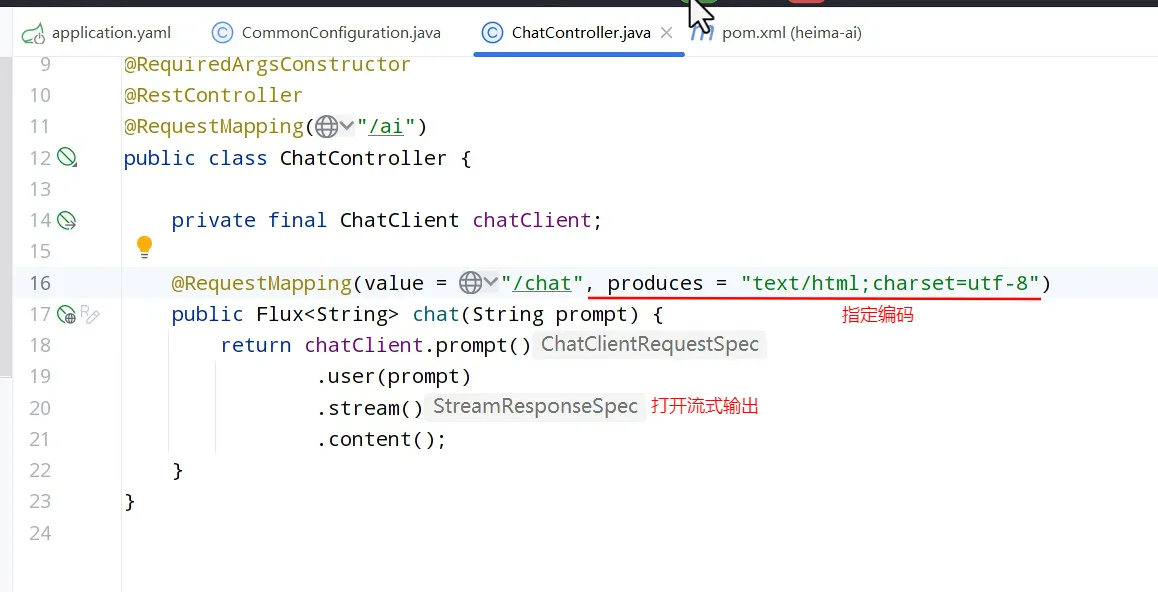
流式调用
- 出现乱码可以对接口进行指定编码,produces

消息注解
- 用于限定AI回答的范围

会话记忆
- 大模型是不具备记忆能力的,要想让大模型记住之前聊天的内容,唯一的办法就是把之前聊天的内容与新的提示词一起发给大模型。

- langchain4j提供了一个接口用于定义会话记忆对象
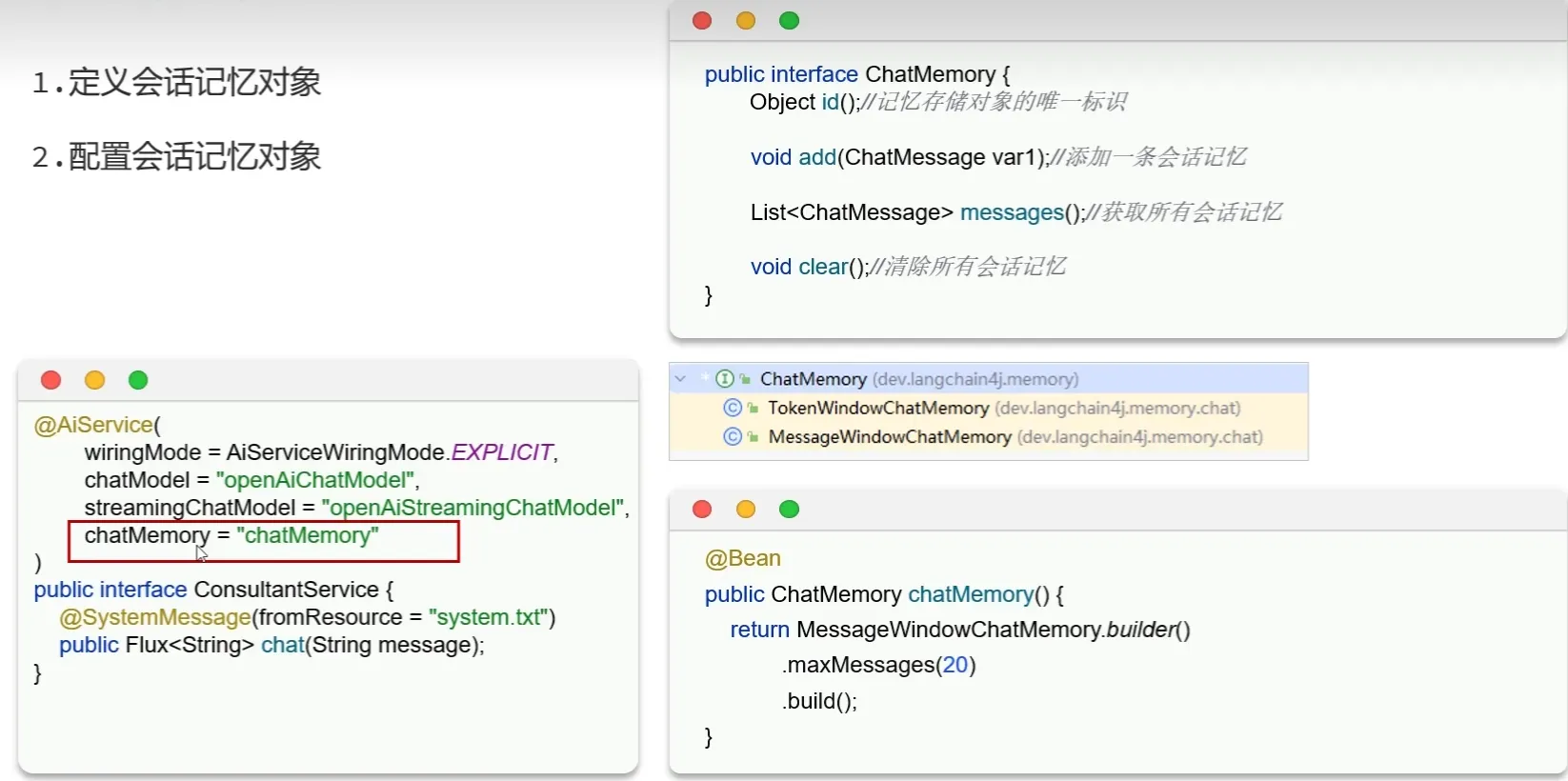

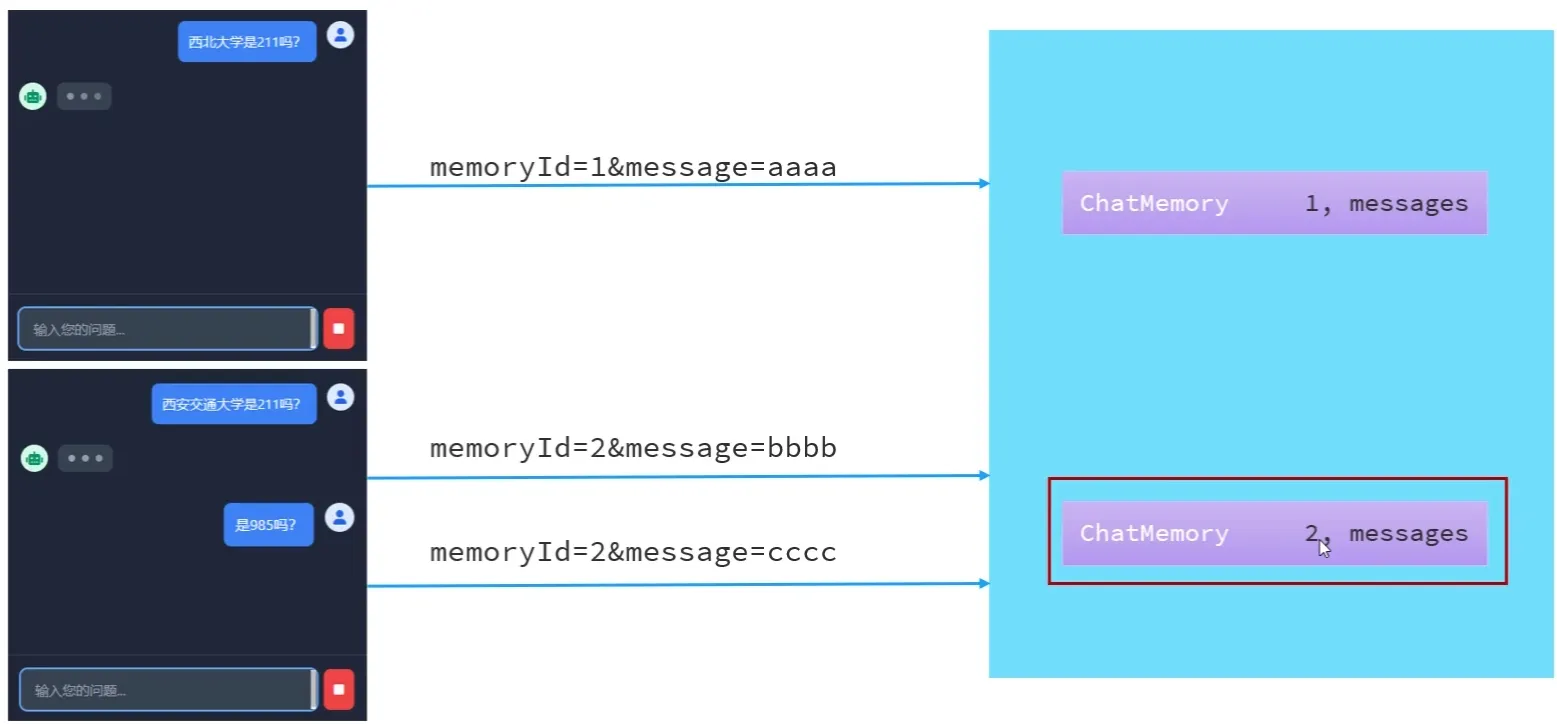
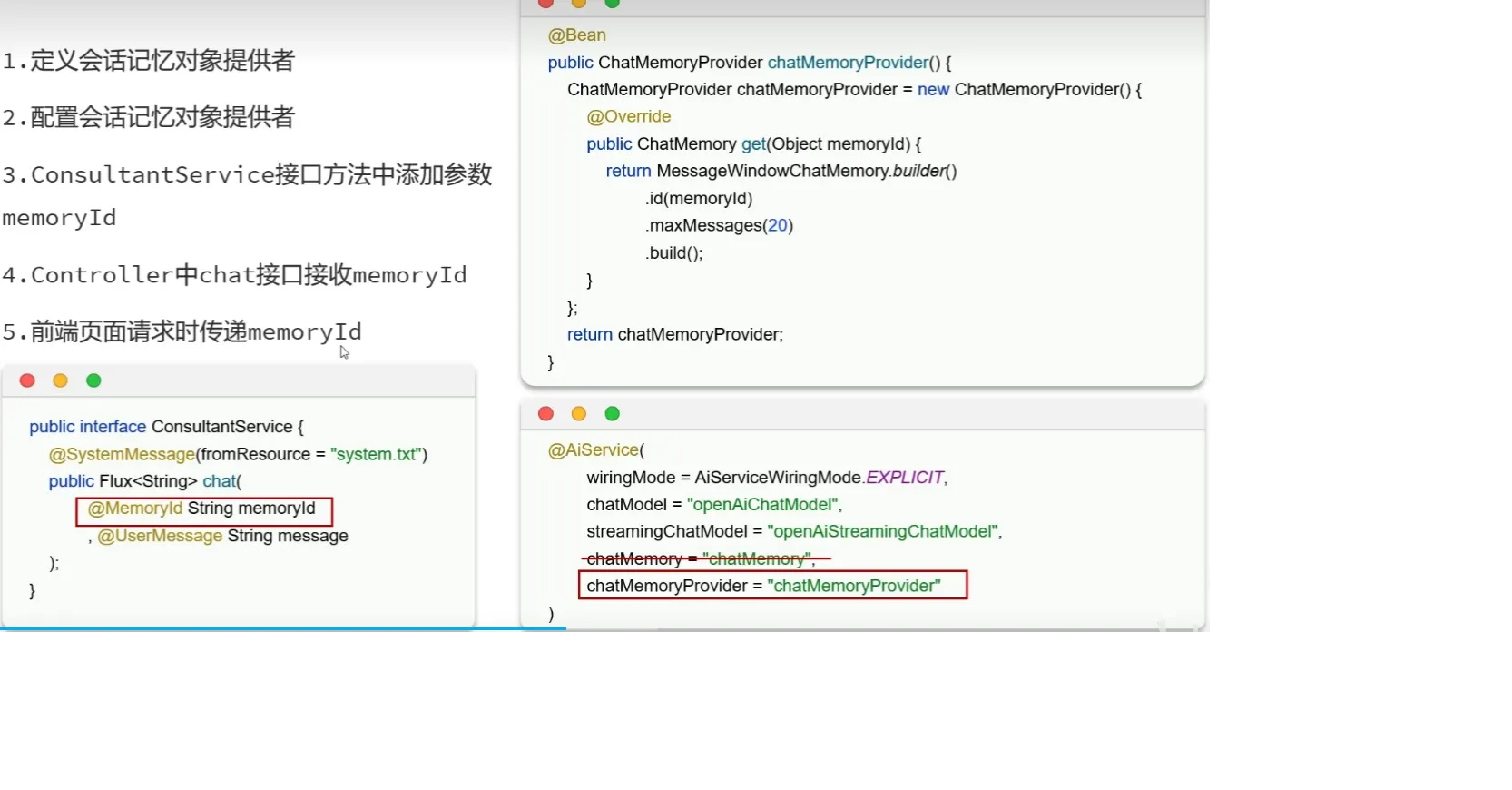
会话隔离
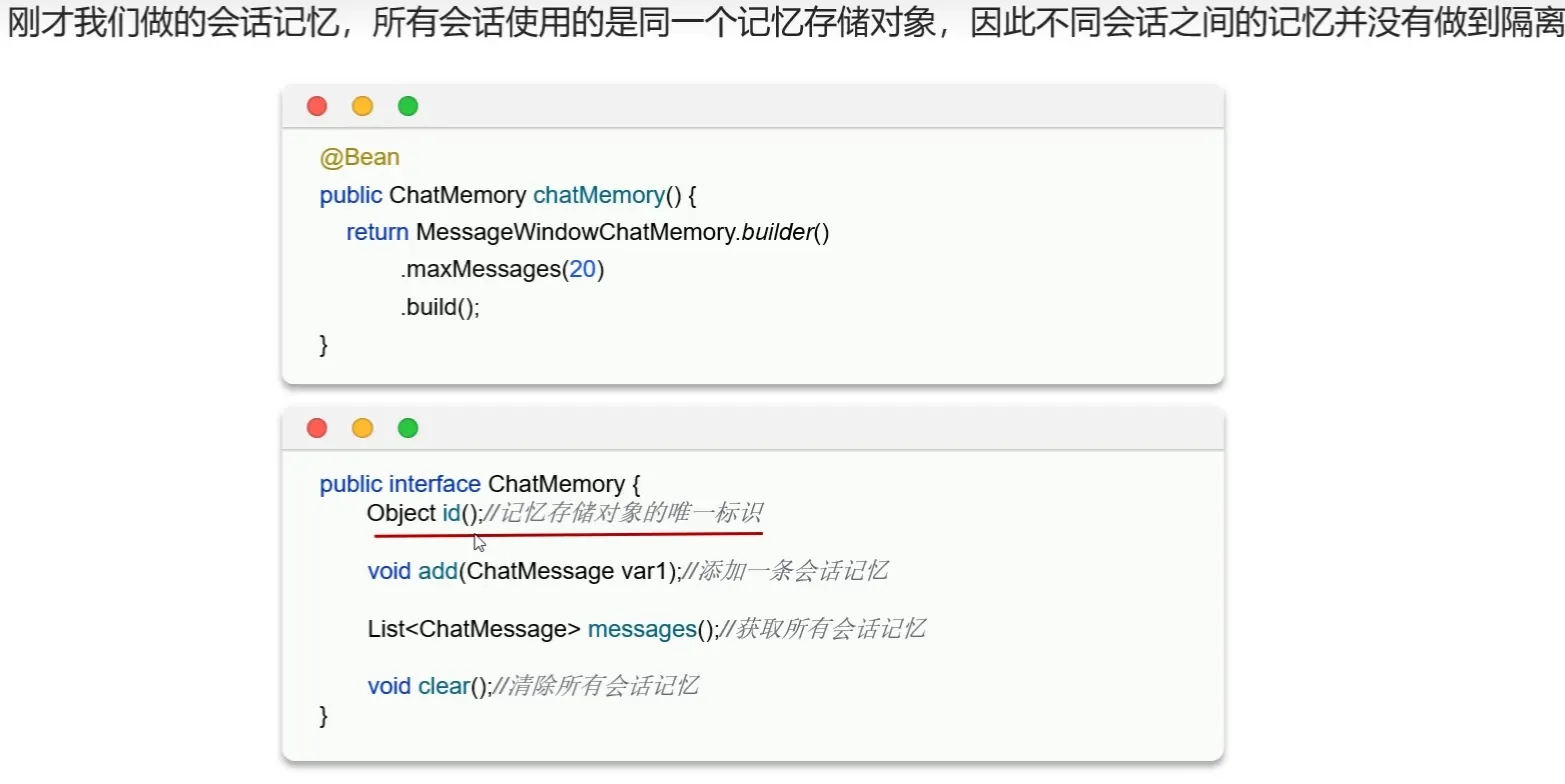
- 原理
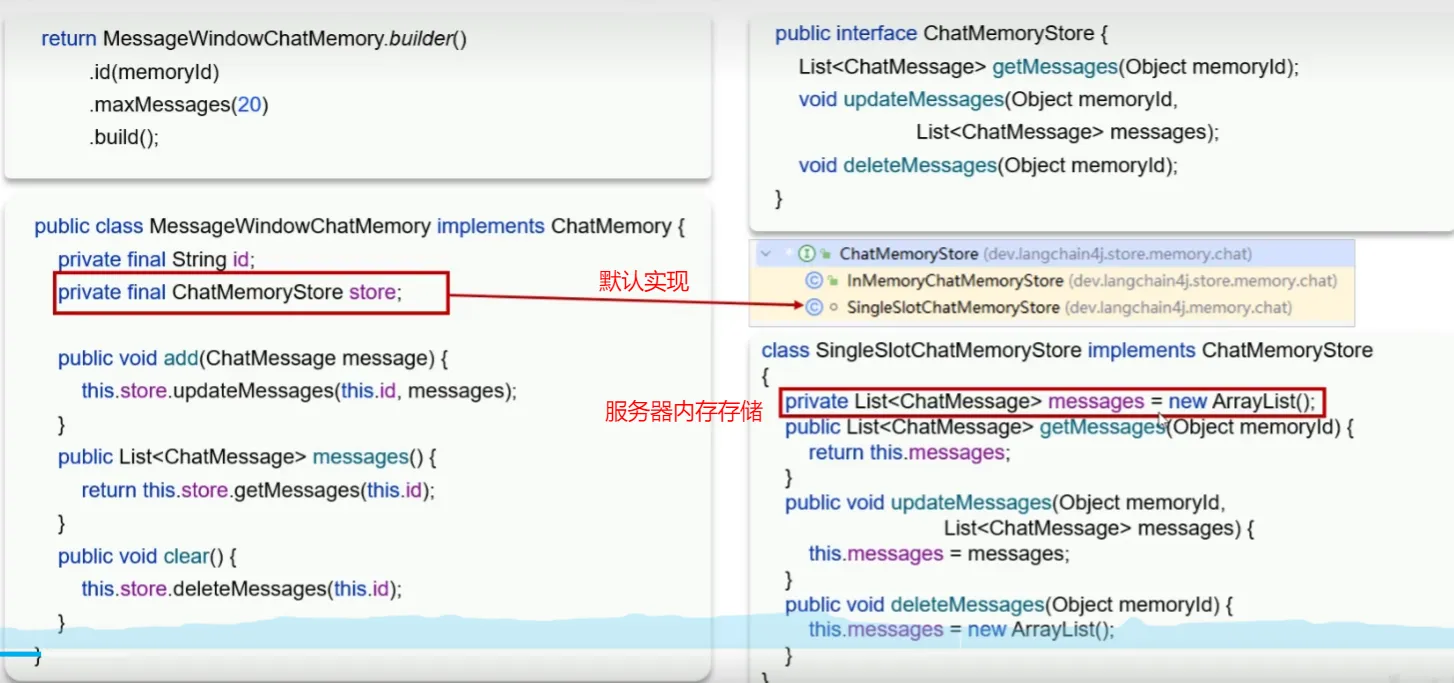
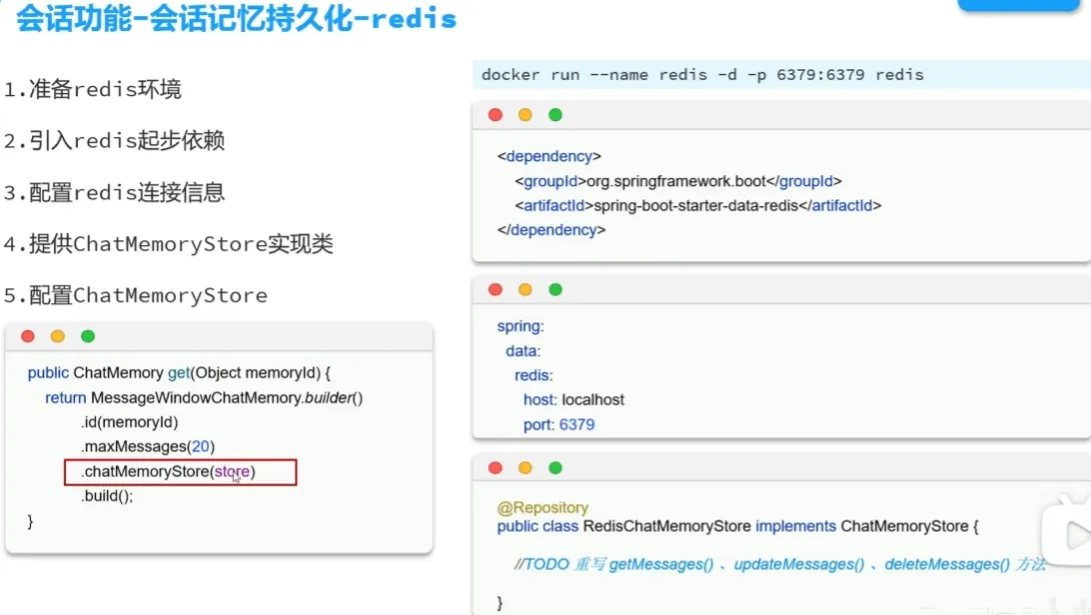
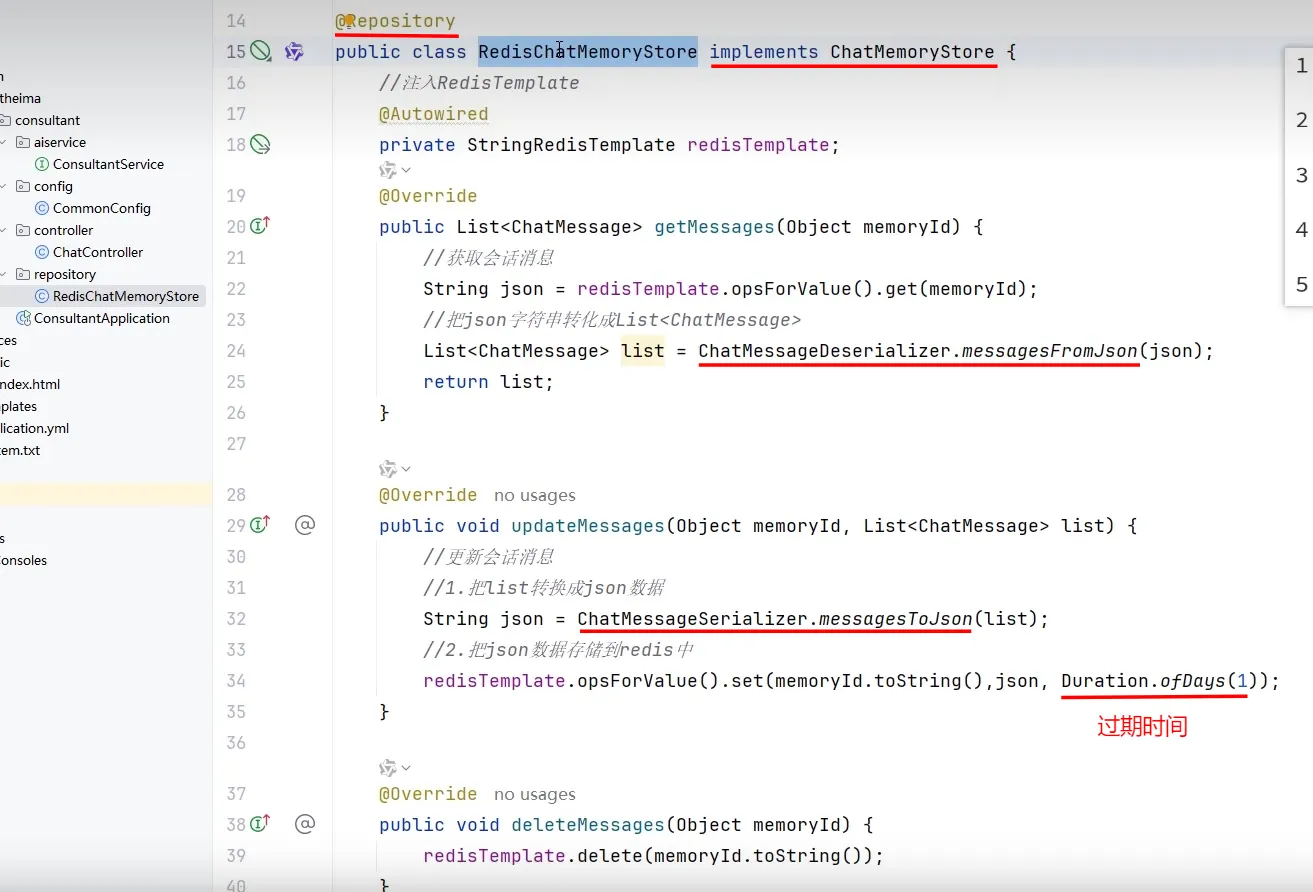
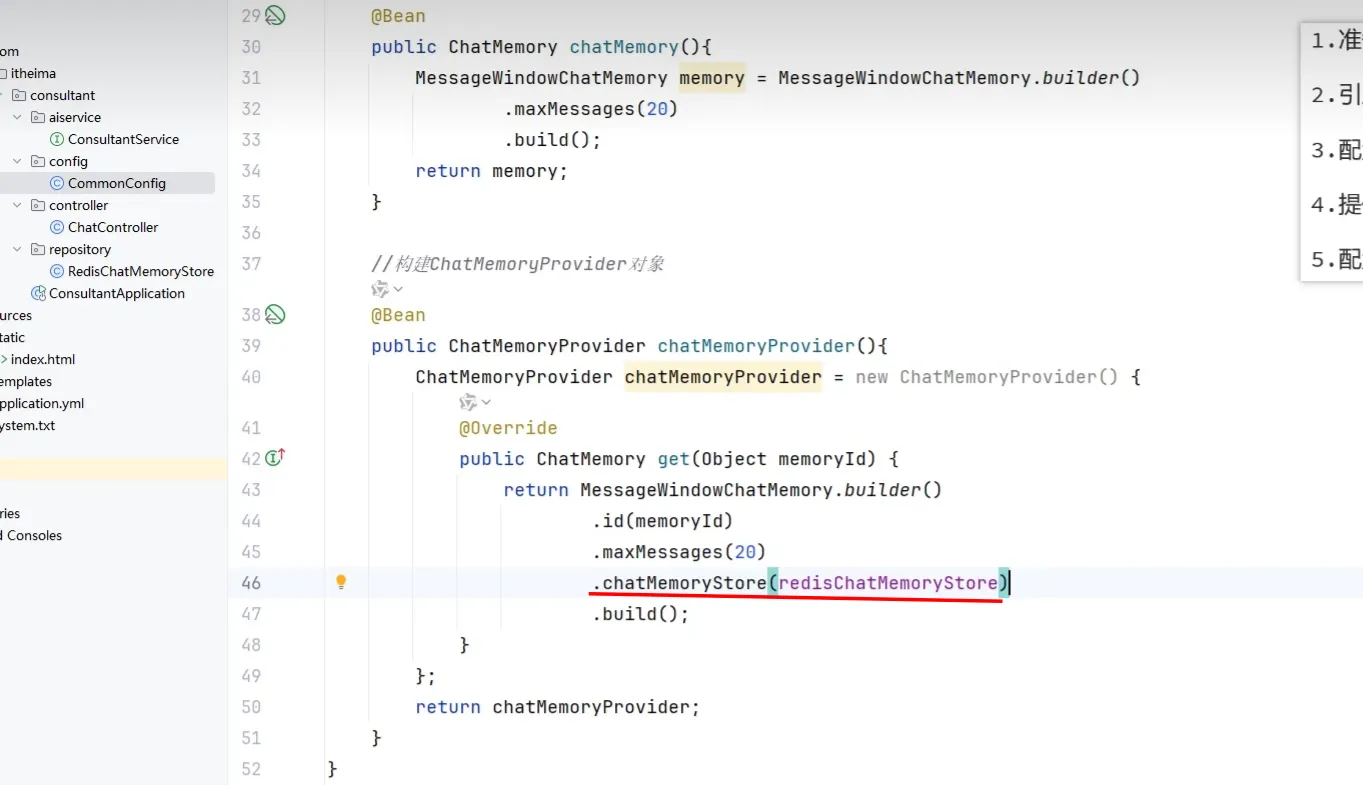
会话记忆持久化
- 刚才我们做的会话记忆,只要后端重启,会话记忆就没有了
- 原因
- 基于redis做持久化
RAG知识库
RAG,Retrieval Augmented Generation,检索增强生成。通过检索外部知识库的方式增强大模型的生成能力。
原理
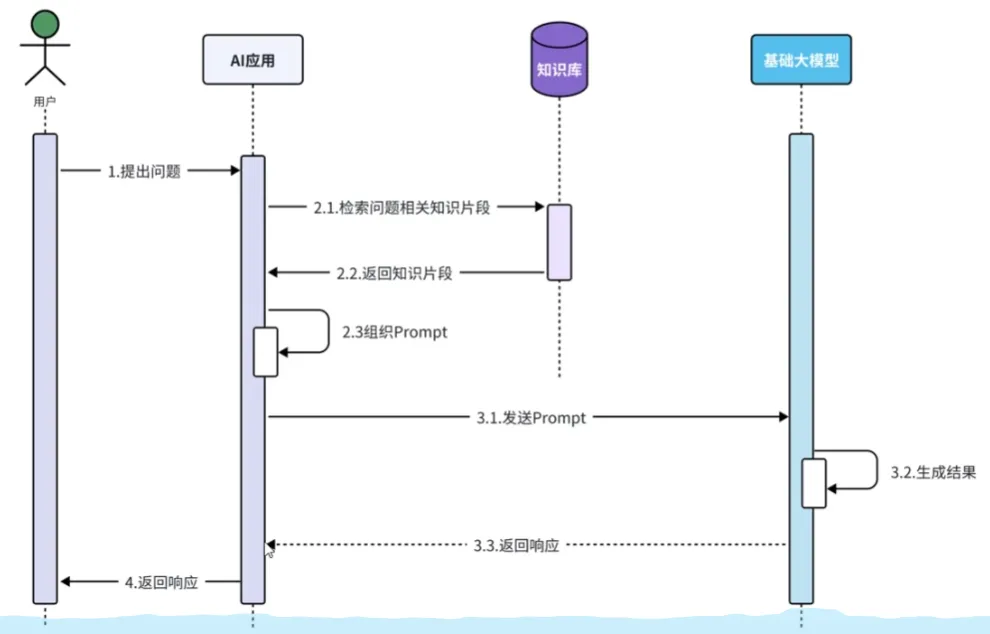
- 向量数据库:
- Milvus、Chroma、Pinecone
- RedisSearch(Reids)、pgvector(PostgreSQL)

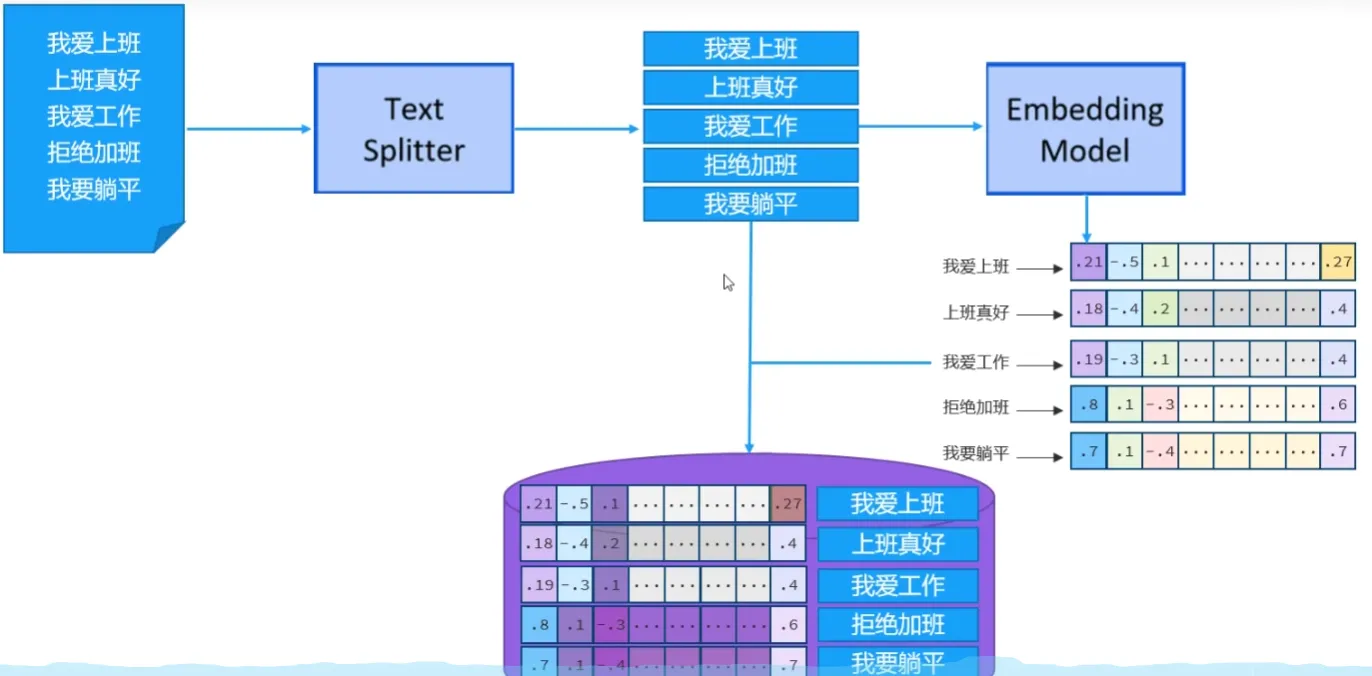
- 如何往向量数据库中存储数据
- 如何检索向量数据库
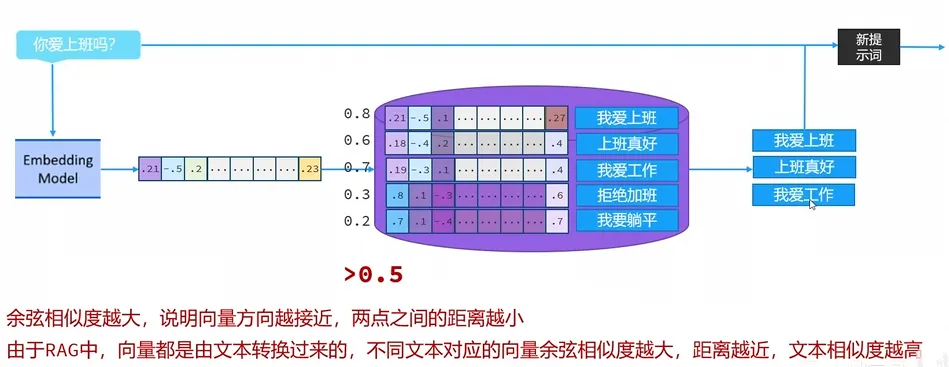
- 总结
- 两个向量的余弦相似度越高,说明向量对应的文本相似度越高
- 向量数据库使用流程
- 借助于向量模型,把文档知识数据向量化后存储到向量数据库
- 用户输入的内容,借助于向量模型转化为向量后,与数据库中的向量通过计算余弦相似度的方式,找出相似度比较高的文本片段
快速入门
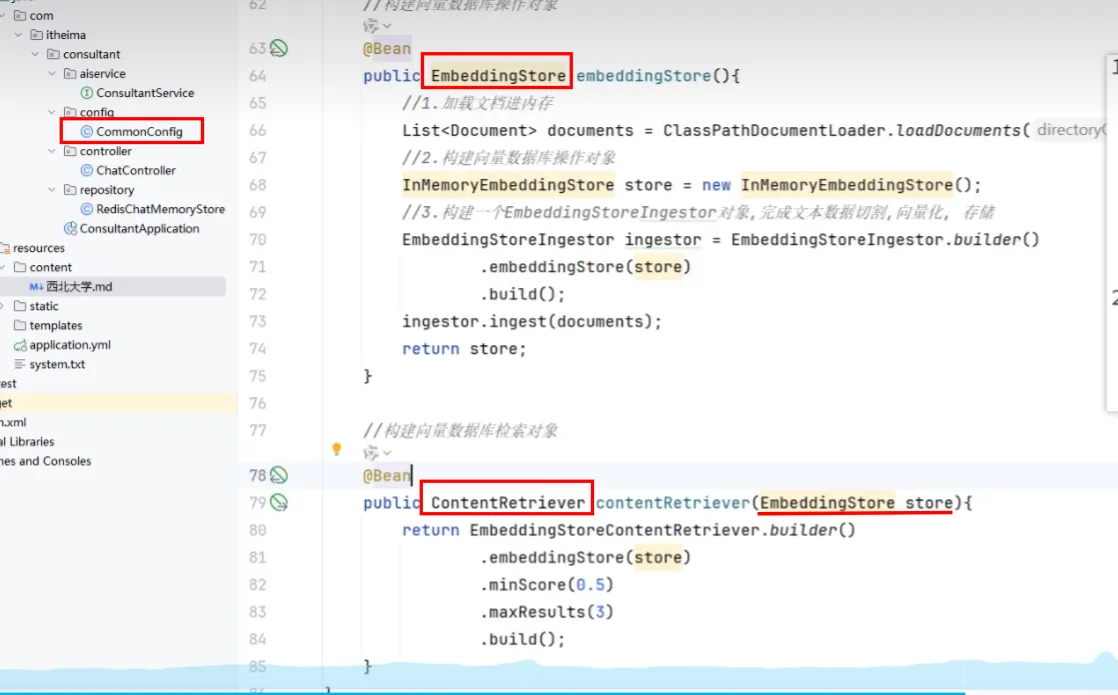
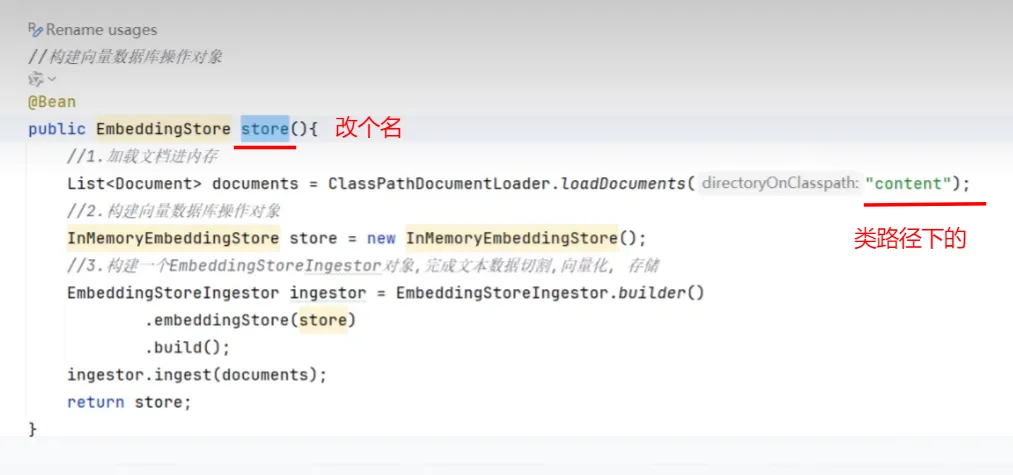
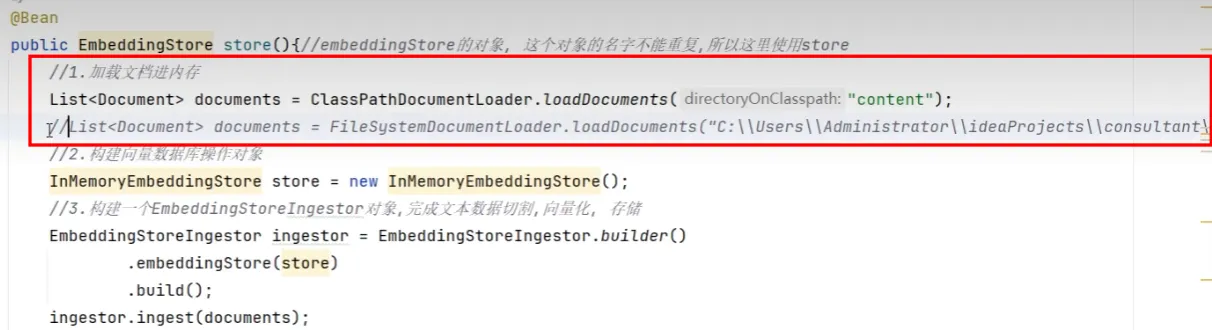
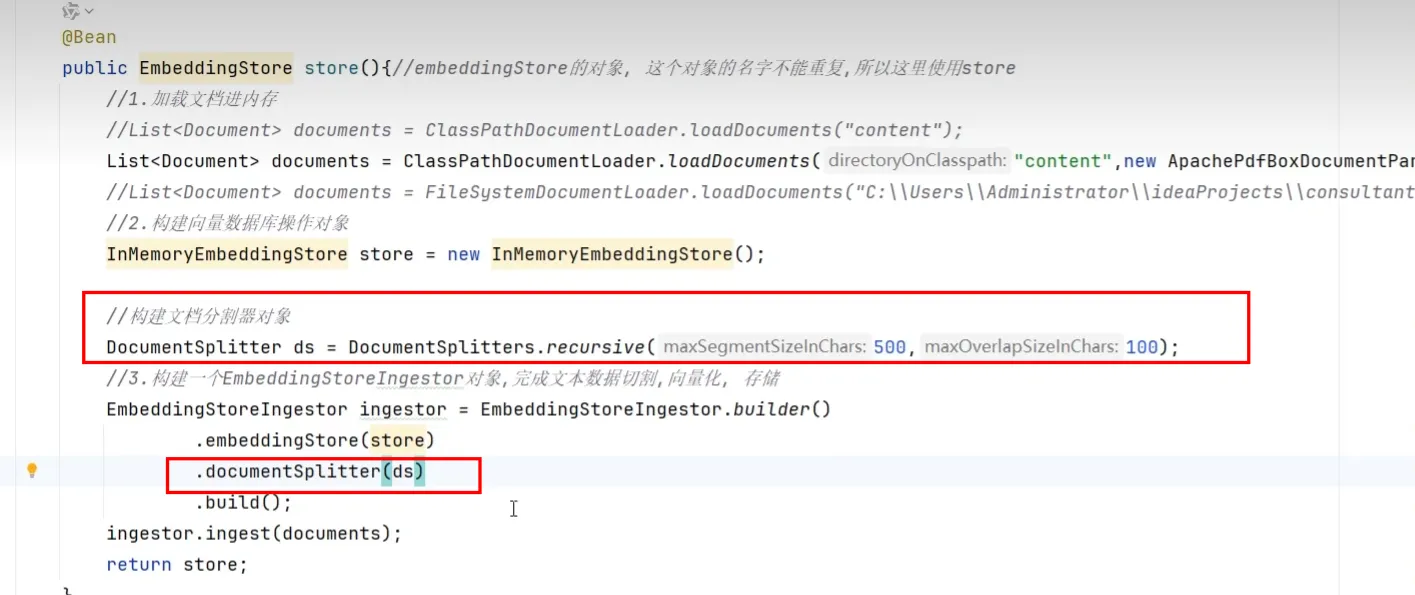
存储(构建向量数据库操作对象)
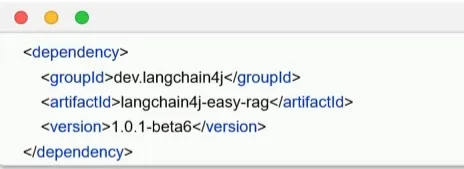
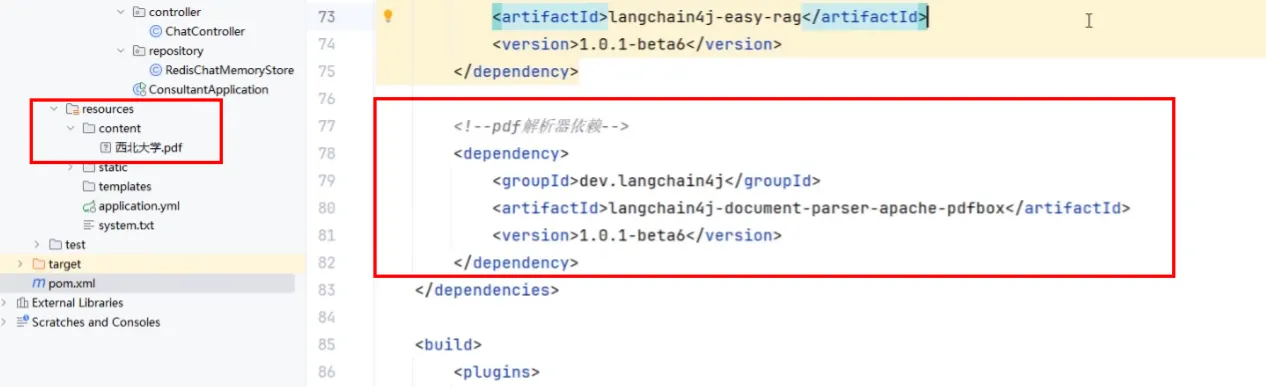
- 引入依赖
- 加载知识数据文档
- 构建向量数据库操作对象
- 把文档切割、向量化并存储到向量数据库中



检索(构建向量数据库检索对象)
- 构建向量数据库检索对象
- 配置向量数据库检索对象


外挂知识库示例

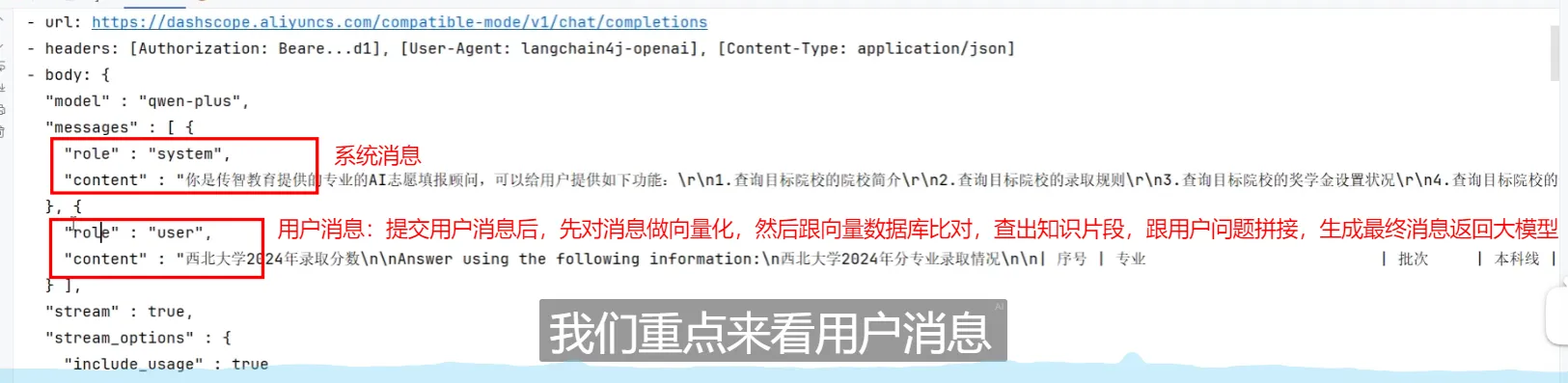
核心API
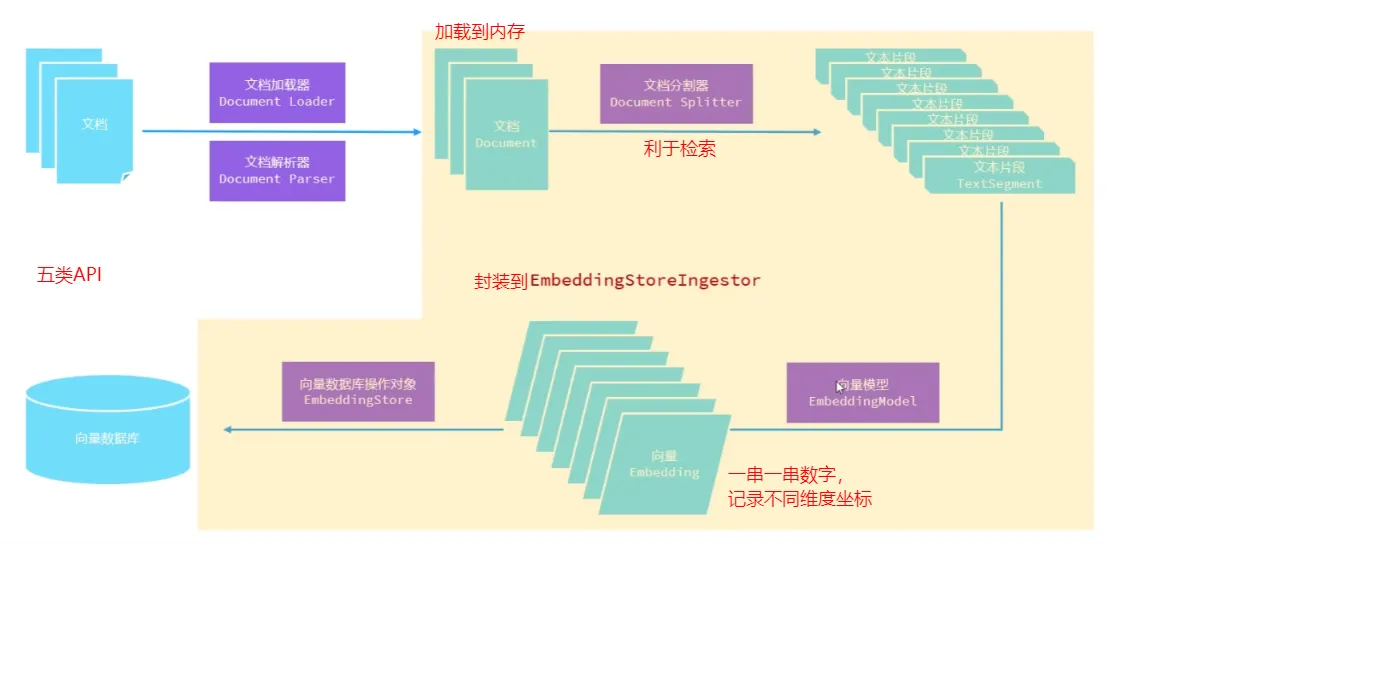
文档加载器

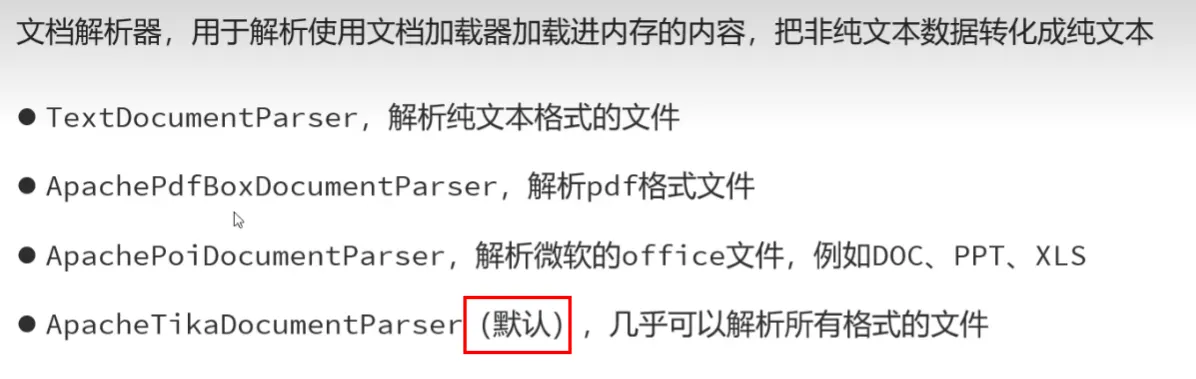
文档解析器
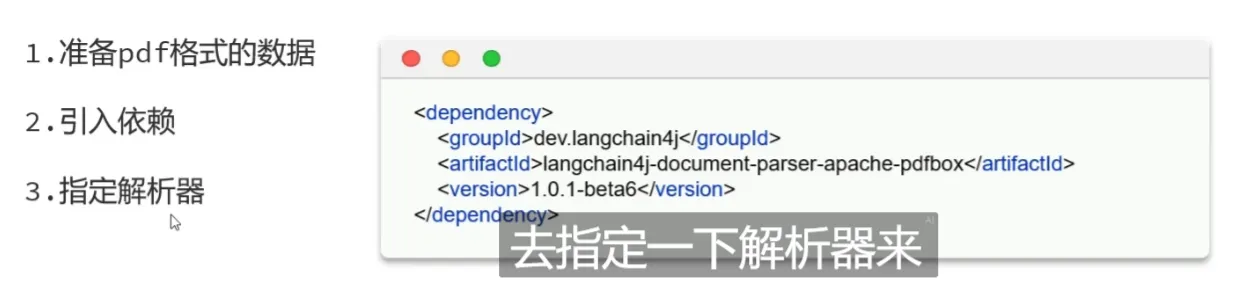

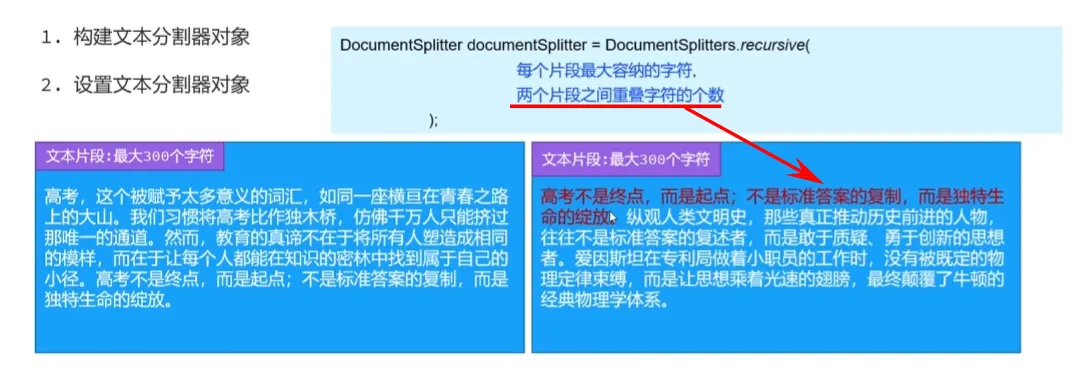
文档分割器


向量模型
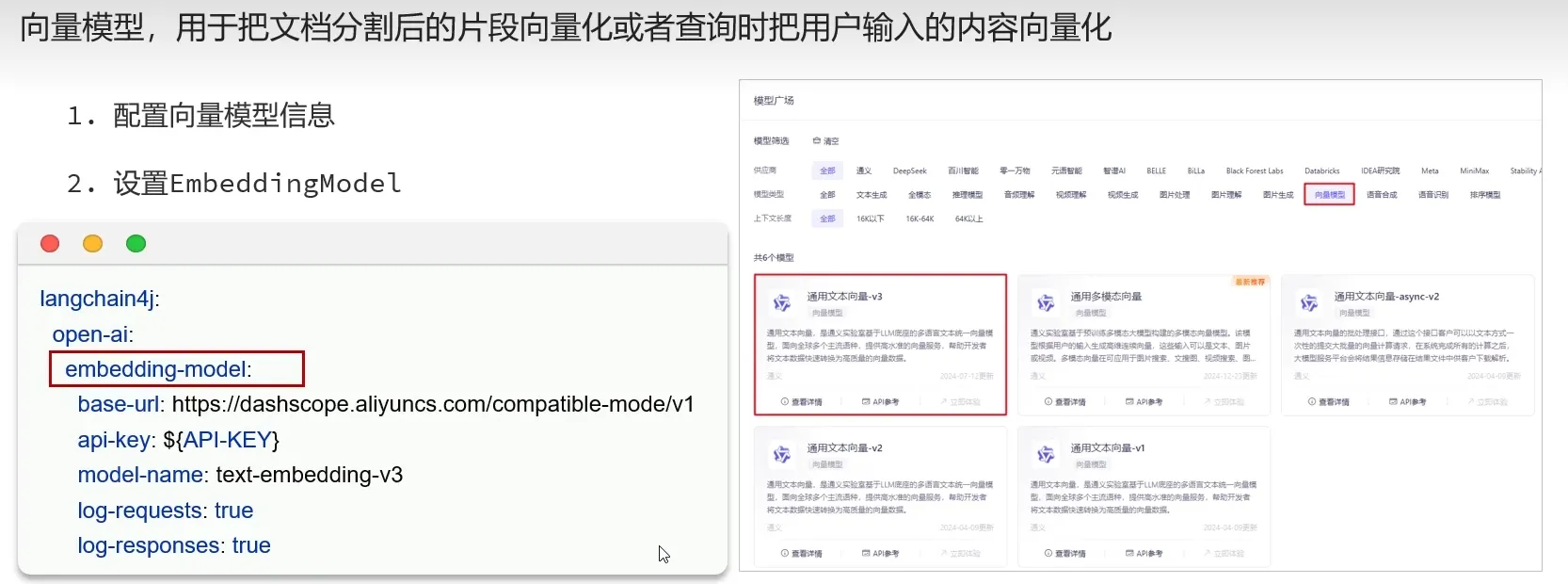
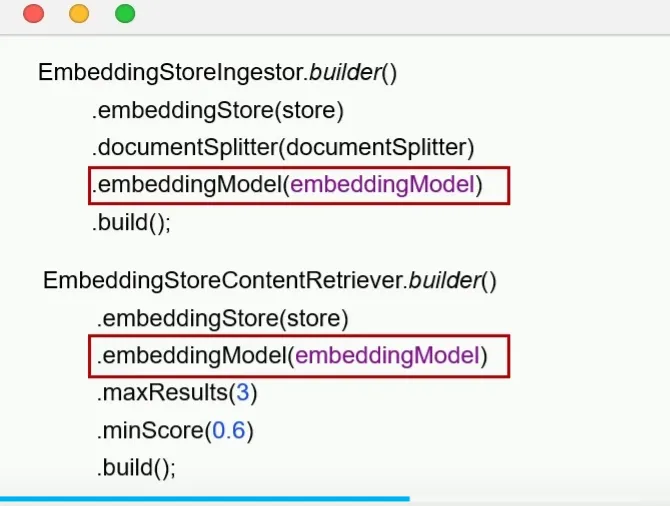
向量数据库
默认的向量数据库是基于内存的,重启就丢失了,需要持久化

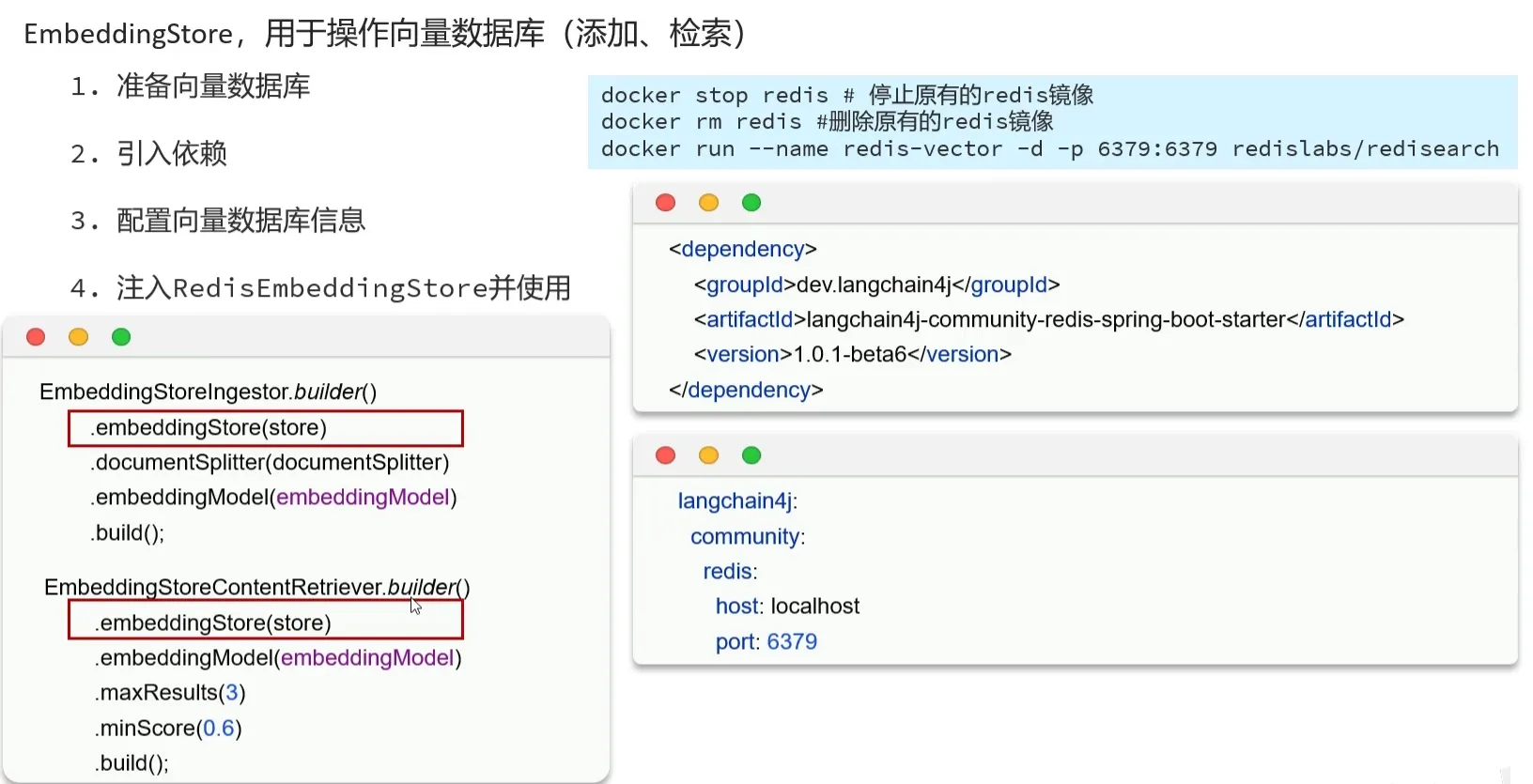
- 为了能正确加载,需要做个配置
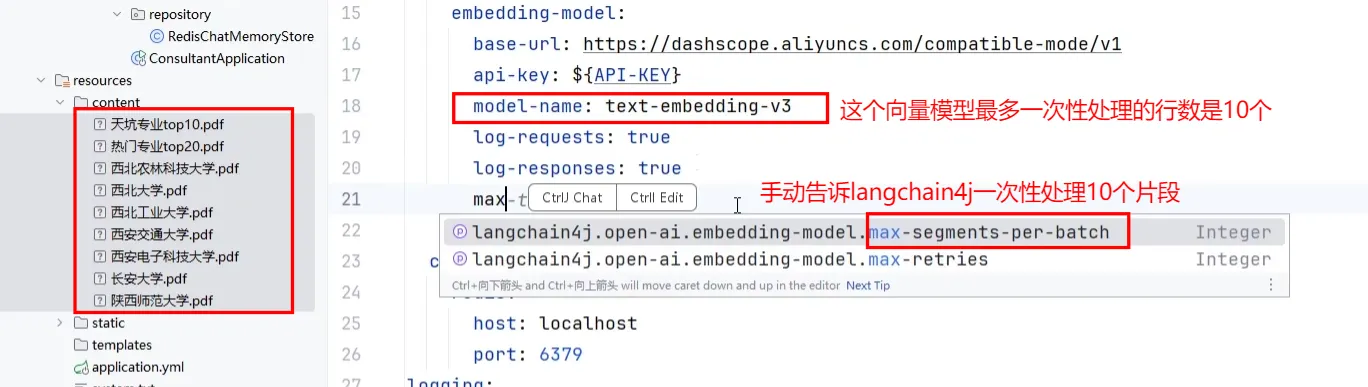
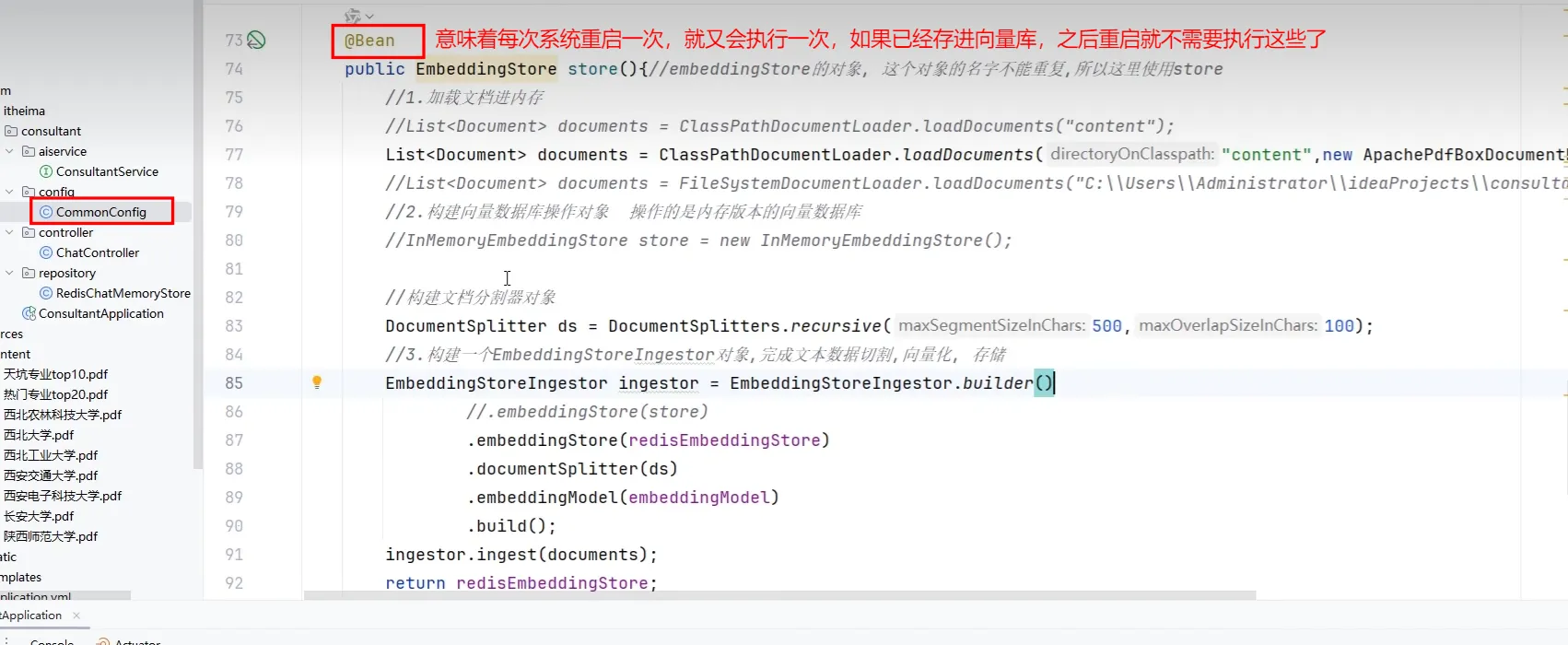
- 所以当向量库中有了数据后,这个@Bean就可以注释掉了
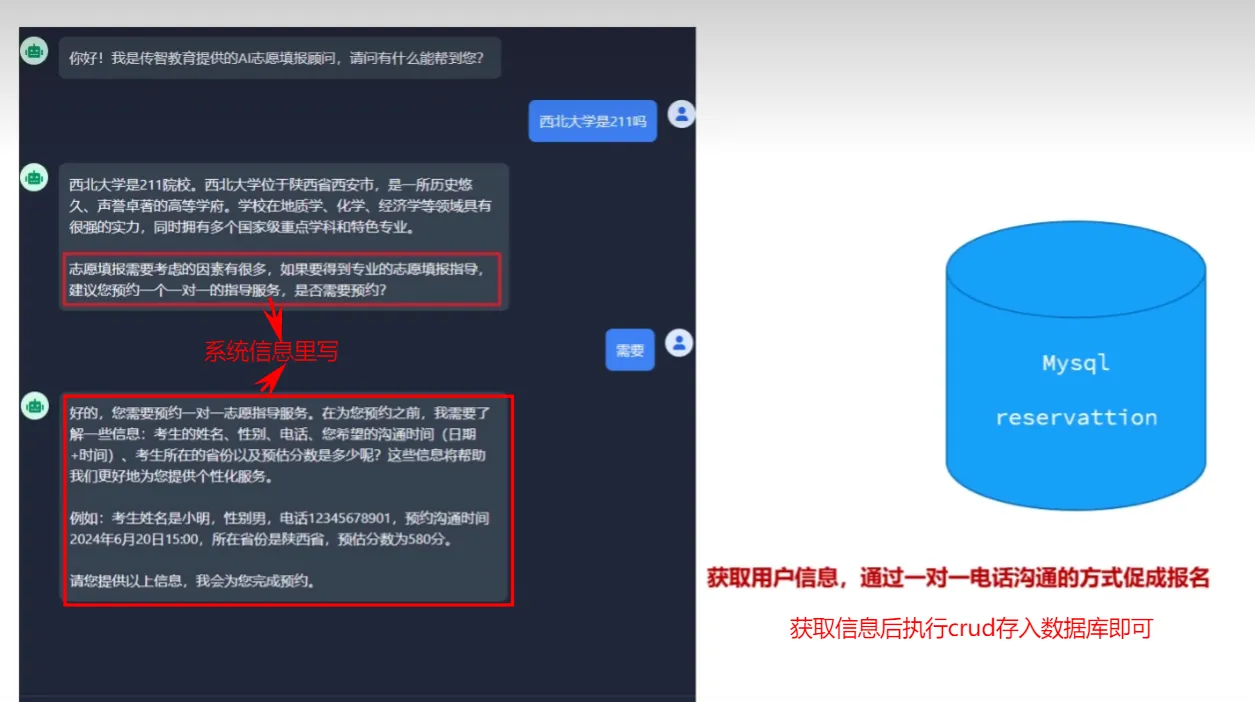
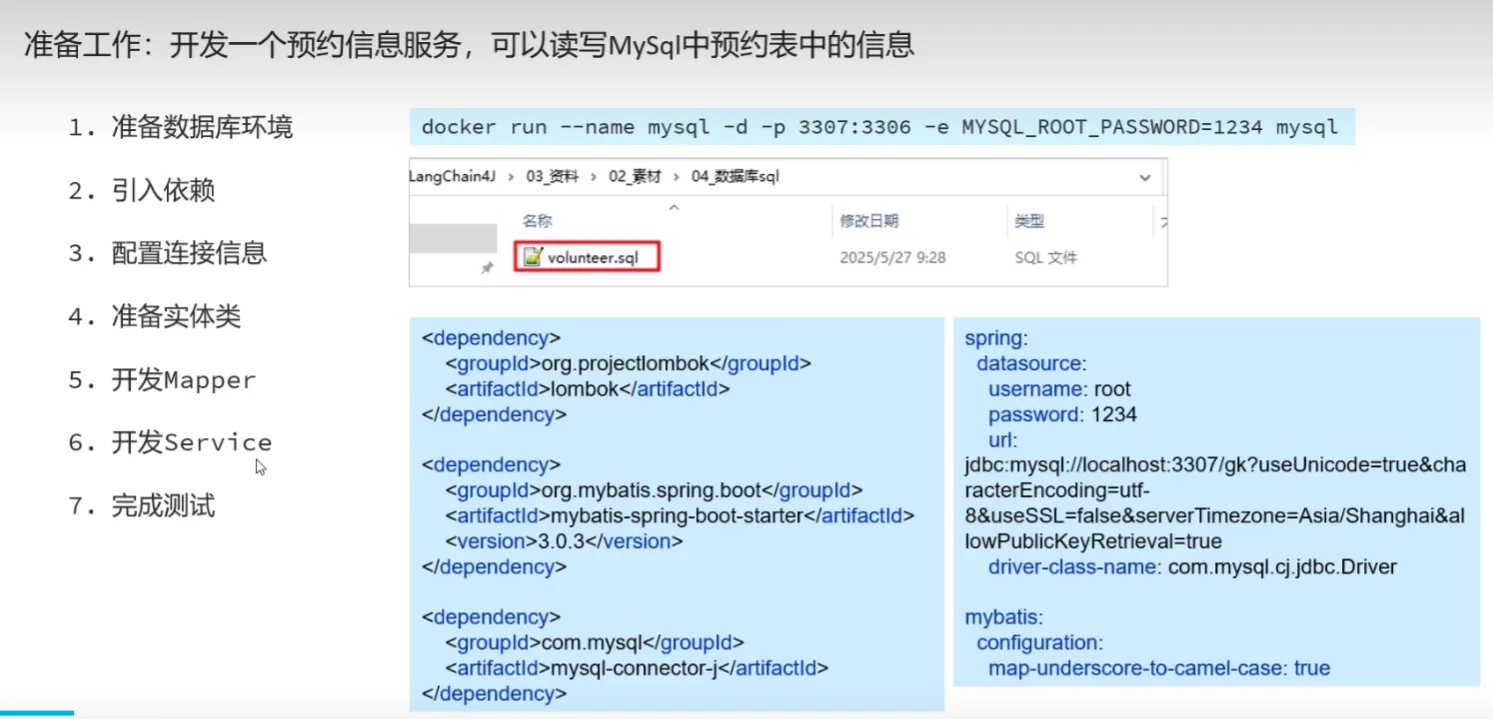
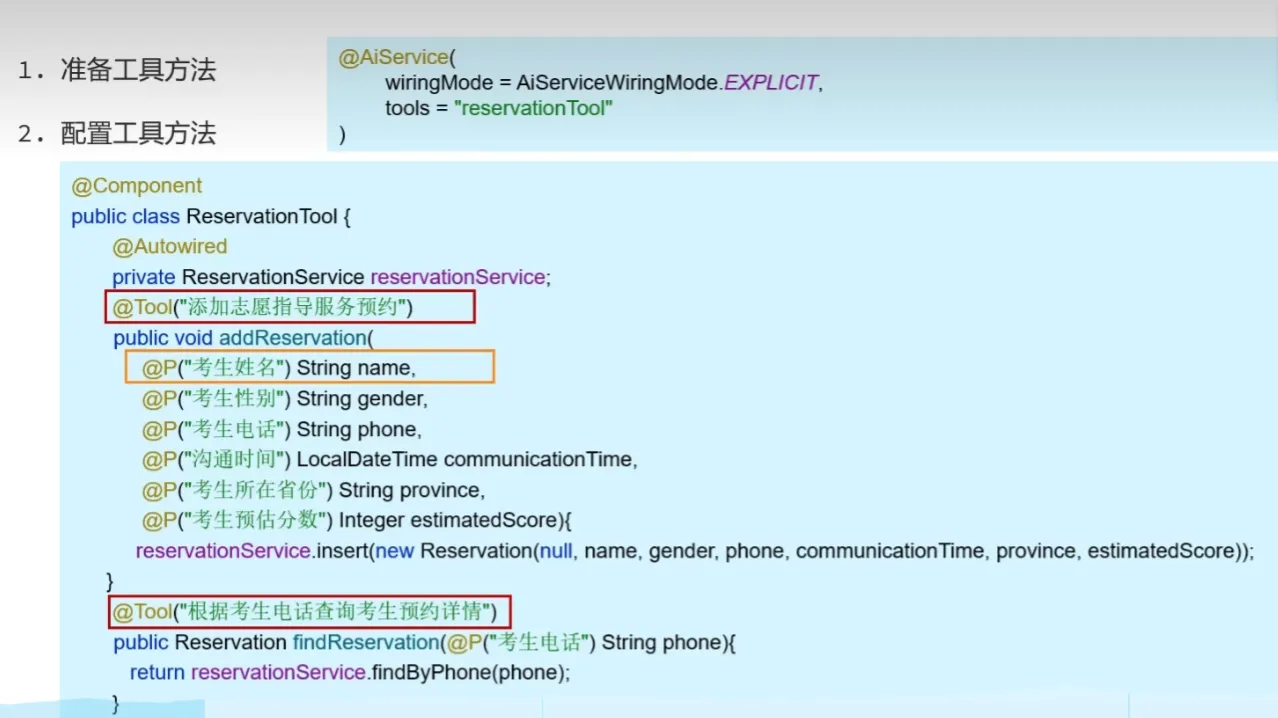
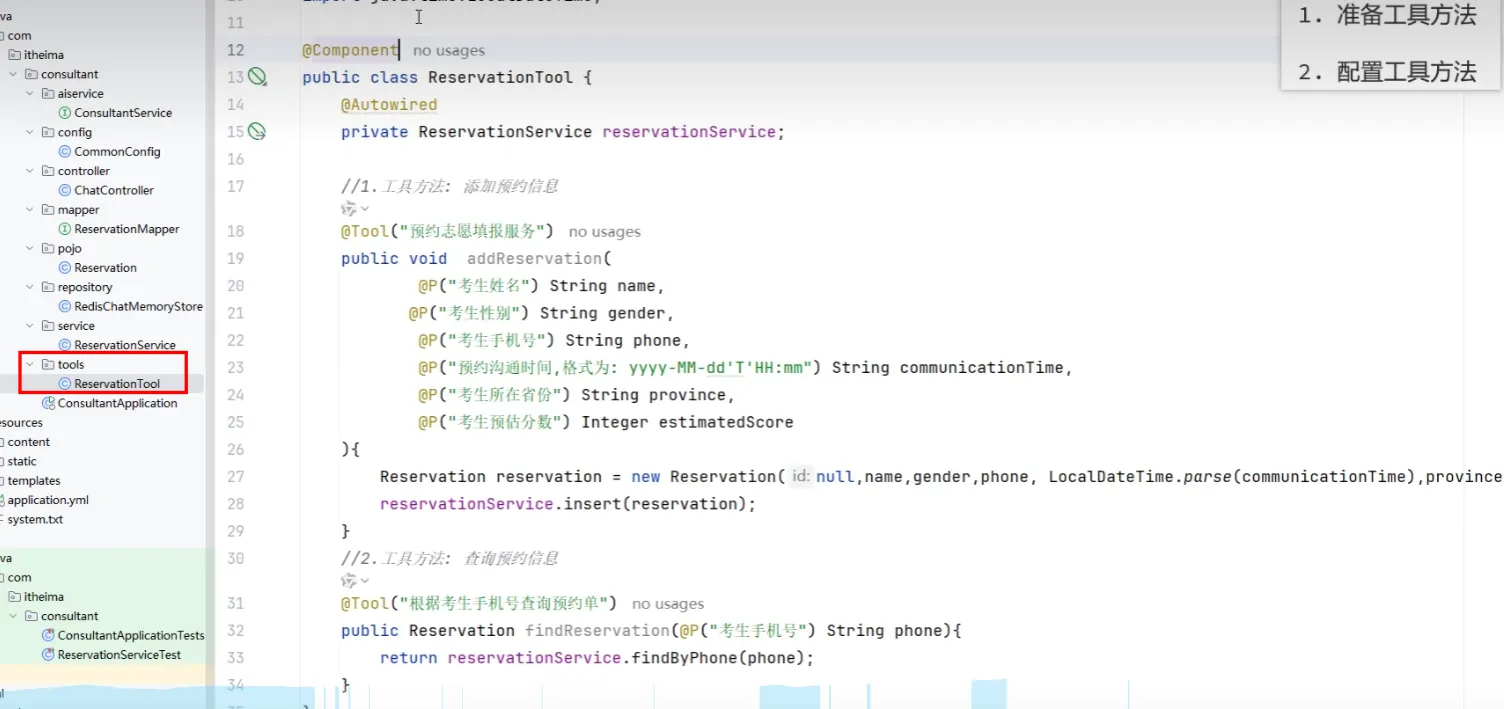
Tools工具
评论


